- Sviluppatori
-
-
COMUNITÀ

Unirsi alla comunità degli sviluppatori
Esplora le risorse per gli sviluppatori, gli ambasciatori e gli eventi nella tua zona.
Per saperne di più
-
-
Couchbase Multi-Dimensional Scaling è una tecnologia di database innovativa che aumenta sostanzialmente le prestazioni delle applicazioni e riduce drasticamente i costi. Il Multi-Dimensional Scaling consente di ottenere questi vantaggi grazie alla possibilità di separare, isolare e scalare i singoli servizi di database (query, indici e dati), permettendo di supportare più di un profilo hardware in modo da ottimizzare le risorse per un singolo servizio. Il risultato è che è possibile eseguire query complesse, creare indici illimitati e continuare a scalare i dati su molti nodi senza preoccuparsi delle prestazioni.
Altri database, come MongoDB, Oracle e Cassandra, hanno un approccio limitante alla scalabilità, che costringe a eseguire ogni servizio di database su ogni nodo. Questo approccio porta alla contesa delle risorse, a prestazioni più lente, a capacità di interrogazione limitate e all'overprovisioning. Couchbase Server con Multi-dimensional Scaling elimina tutte queste limitazioni, garantendo maggiori prestazioni, su scala più ampia e a costi inferiori.
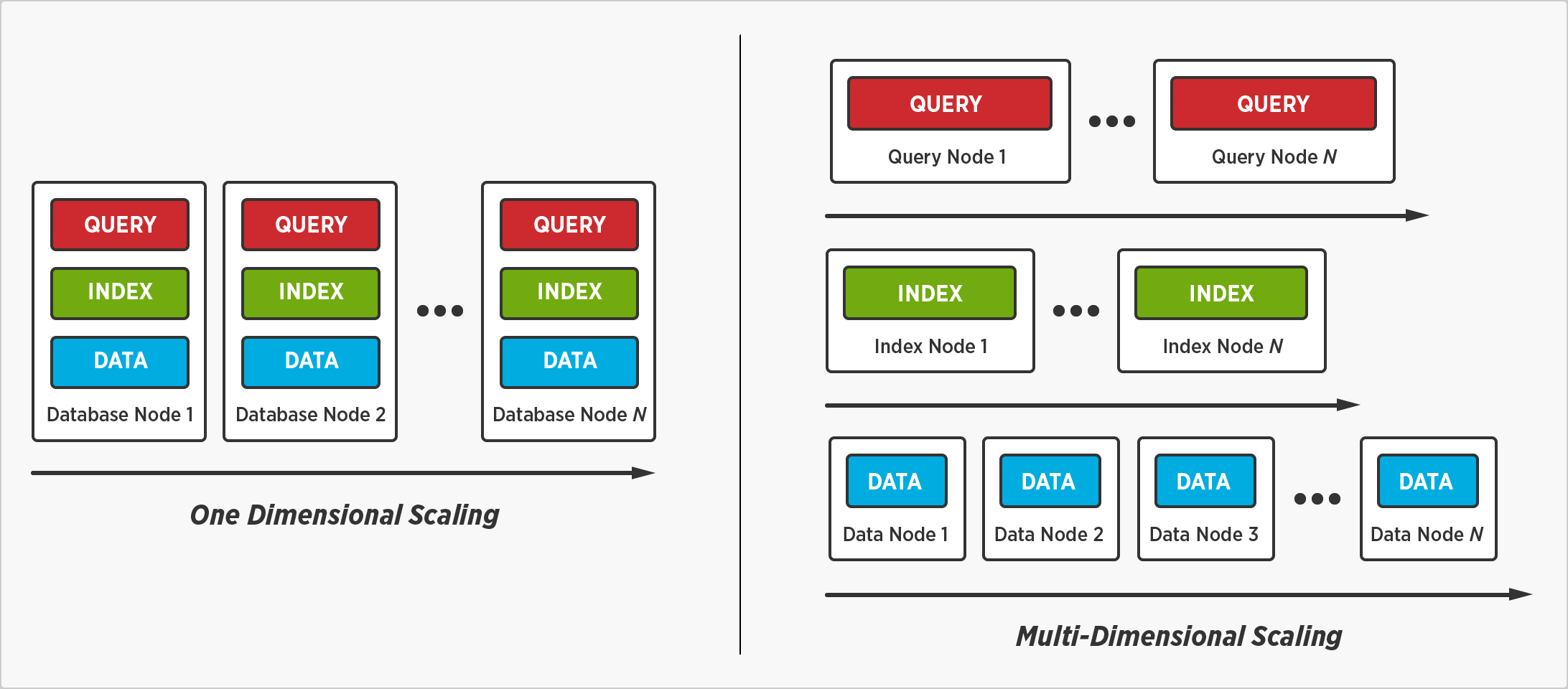
Perché è necessaria la scalatura multidimensionale?
La scalabilità di un'architettura distribuita è ottima per i dati, ma rappresenta una sfida per gli indici e le query. In parole povere, la scalabilità dei dati accelera le letture e le scritture, ma rallenta le query, e la creazione di indici accelera le query, ma rallenta le scritture. Ad esempio, se si ridimensiona il database per supportare un'enorme quantità di dati, le prestazioni delle query ne risentiranno drasticamente, perché più sono i nodi che partecipano a una query distribuita, peggiore è il suo rendimento. Inoltre, la creazione di molti indici per migliorare le prestazioni delle query avrà un impatto negativo sulle prestazioni di scrittura, perché le scritture non vengono completate finché tutti gli indici non sono stati aggiornati. In conclusione, lo scaling out, con ogni servizio di database in esecuzione su ogni nodo, può comportare un forte calo dell'efficienza e delle prestazioni.
In che modo i servizi di database beneficiano dell'isolamento?
Le interrogazioni richiedono processori veloci
Se una query può essere eseguita da un singolo nodo o da molte query da molti nodi, i risultati saranno restituiti più velocemente e non rallenteranno le letture e le scritture monopolizzando il tempo della CPU.
Gli indici richiedono SSD ad alte prestazioni
Se un indice può essere memorizzato su un singolo nodo, o molti indici su molti nodi, può essere cercato più velocemente e non rallenterà le scritture monopolizzando l'IO del disco.
I dati sono il motivo principale di un database distribuito
Più nodi si hanno, più dati si possono memorizzare. Questi nodi beneficiano di una maggiore memoria, ma richiedono meno CPU e disco. Quando i dati sono isolati dalle query e dagli indici, le prestazioni di lettura e scrittura non solo migliorano, ma rimangono costanti.
Vantaggi dell'isolamento
| Interrogazione | Indice | Dati | |
|---|---|---|---|
| Ottimizzazione delle risorse | Elaborazione | Immagazzinamento | Memoria |
| Vantaggi dell'isolamento | Le query sono più veloci.
Le query non rallentano la lettura o la scrittura. Il ridimensionamento del servizio di query non obbliga a riequilibrare i dati. Nessuna contesa di CPU con i servizi di indice e dati.
|
La ricerca negli indici è più veloce. Gli indici non rallentano le scritture. Il ridimensionamento del servizio di indicizzazione non obbliga a riequilibrare i dati. Nessuna contesa di IO su disco con il servizio dati. Nessun limite al numero di indici.
|
Le letture e le scritture sono più veloci.
La scalabilità dei dati non rallenta le query o le ricerche negli indici. Il ridimensionamento del servizio dati non obbliga a riequilibrare gli indici. Nessuna contesa di risorse con i servizi di query e indice.
|
| Requisiti hardware | Processore veloce
Meno memoria HDD
|
Processore di base
Meno memoria SSD
|
Processore di base
Più memoria HDD o SSD
|
Come funziona la scalatura multidimensionale
Lo scaling multidimensionale consente di separare e isolare i servizi di database - query, indicizzazione e dati - in modo da poter scalare e ottimizzare le risorse per ciascuno di essi in base al proprio carico di lavoro individuale.
- Le query e gli indici avranno prestazioni migliori perché non richiedono più ogni nodo.
- L'intera applicazione avrà prestazioni migliori, poiché le letture, le scritture e le query non competeranno più per le risorse condivise.
- I costi dell'hardware si ridurranno perché si potranno utilizzare server più grandi per le query e gli indici e server più piccoli per i dati.
I vantaggi sono immediati e di grande impatto.
Vantaggio tecnico
- Miglioramento delle prestazioni delle applicazioni
- Miglioramento della stabilità dell'applicazione
- Miglioramento dell'utilizzo delle risorse
- Miglioramento dell'efficienza operativa
Vantaggi per l'azienda
- Migliore esperienza del cliente
- Esperienza cliente coerente
- Riduzione dei costi dell'hardware
- Riduzione delle spese amministrative