Em Parte 1 Vimos como extrair o Twitter, transformar tweets em documentos JSON, obter uma representação de incorporação desse tweet, armazenar tudo no Couchbase e como executar uma pesquisa vetorial. Essas são as primeiras etapas de uma arquitetura de Geração Aumentada de Recuperação que poderia resumir um tópico do Twitter. A próxima etapa é usar um modelo de linguagem grande. Podemos solicitar que ele resuma a discussão e podemos enriquecer o contexto da solicitação graças à pesquisa vetorial.
LangChain e Streamlit
Então, como fazer com que tudo isso funcione em conjunto com um LLM? É aí que o projeto LangChain pode ajudar. Seu objetivo é permitir que os desenvolvedores criem aplicativos baseados em LLM. Já temos alguns exemplos disponíveis em GitHub que mostram nosso módulo LangChain. Como esta demonstração do RAG, que permite que o usuário carregue um PDF, vetorize-o, armazene-o no Couchbase e use-o em um chatbot. Esse está em JavaScript, mas há também um Versão Python.
Acontece que isso é exatamente o que eu quero fazer, só que usando um PDF em vez de uma lista de tweets. Então, eu o bifurquei e comecei a brincar com ele aqui. Aqui, Nithish está usando algumas bibliotecas interessantes, LangChain, é claro, e Streamlit. Outra coisa legal para aprender! O Streamlit é como um PaaS com baixo código e ciência de dados serviço. Ele permite que você implemente aplicativos baseados em dados com muita facilidade, com o mínimo de código, de uma forma muito, muito opinativa.
Configuração
Vamos dividir o código em partes menores. Podemos começar com a configuração. O método a seguir garante que as variáveis de ambiente corretas estejam definidas e interrompe a implantação do aplicativo se elas não estiverem.
O check_environment_variable é chamado várias vezes para garantir que a configuração necessária esteja definida e, se não estiver, interromperá o aplicativo.
|
1 2 3 4 5 |
def check_environment_variable(nome_da_variável): """Verifique se a variável de ambiente está definida""" se nome_da_variável não em os.ambiente: st.erro(f"A variável de ambiente {variable_name} não está definida. Por favor, adicione-a ao arquivo secrets.toml") st.parar() |
|
1 2 3 4 5 6 7 8 |
check_environment_variable("OPENAI_API_KEY") # A chave da API OpenApi que criei e usei anteriormente check_environment_variable("DB_CONN_STR") # Uma string de conexão para se conectar ao Couchbase, como couchbase://localhost ou couchbases://cb.abab-abab.cloud.couchbase.com check_environment_variable("DB_USERNAME") Nome de usuário # check_environment_variable("DB_PASSWORD") # E a senha para se conectar ao Couchbase check_environment_variable("DB_BUCKET") # O nome do bucket que contém nossos escopos e coleções check_environment_variable("DB_SCOPE") Escopo # check_environment_variable("DB_COLLECTION") # e o nome da coleção, você pode pensar em uma coleção como uma tabela no RDBMS check_environment_variable("INDEX_NAME") # O nome do índice do vetor de pesquisa |
Isso significa que tudo o que está ali é necessário. Uma conexão com OpenAI e para Couchbase. Vamos falar rapidamente sobre o Couchbase. É um banco de dados distribuído JSON e multimodelo com um cache integrado. Você pode usá-lo como K/V, SQL, pesquisa de texto completo, séries temporais, análises, e adicionamos novos recursos fantásticos na versão 7.6: CTEs recursivos para fazer consultas de gráficos, ou o que mais nos interessa hoje, a pesquisa vetorial. A maneira mais rápida de tentar é ir para cloud.couchbase.comO sistema oferece uma avaliação de 30 dias, sem necessidade de cartão de crédito.
A partir daí, você pode seguir as etapas e configurar seu novo cluster. Configure um bucket, um escopo, uma coleção e um índice, um usuário e certifique-se de que o cluster esteja disponível externamente, e você poderá passar para a próxima parte. Obter uma conexão com o Couchbase a partir do aplicativo. Isso pode ser feito com essas duas funções. Você pode ver que elas são anotadas com @st.cache_resource. Ele é usado para armazenar em cache o objeto da perspectiva do Streamlit. Ele o torna disponível para outras instâncias ou repetições. Aqui está o trecho do documento
Decorador para armazenar em cache funções que retornam recursos globais (por exemplo, conexões de banco de dados, modelos de ML).
Os objetos armazenados em cache são compartilhados entre todos os usuários, sessões e repetições. Eles devem ser thread-safe porque podem ser acessados de vários threads simultaneamente. Se a segurança de thread for um problema, considere usar st.session_state para armazenar recursos por sessão.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
de langchain_community.lojas de vetores importação CouchbaseVectorStore de langchain_openai importação OpenAIEmbeddings @st.cache_resource(show_spinner="Conexão com o Vector Store") def get_vector_store( _cluster, db_bucket, Escopo do banco de dados, coleção db, _embedding, nome_do_índice, ): """Retornar o armazenamento de vetores do Couchbase""" vector_store = CouchbaseVectorStore( agrupamento=_cluster, nome_do_balde=db_bucket, nome_do_escopo=Escopo do banco de dados, nome_da_coleção=coleção db, incorporação=_embedding, nome_do_índice=nome_do_índice, texto_chave ) retorno vetor_loja @st.cache_resource(show_spinner="Conectando-se ao Couchbase") def connect_to_couchbase(connection_string, nome de usuário do db, senha_db): """Conecte-se ao couchbase""" de couchbase.agrupamento importação Aglomerado de couchbase.autenticação importação PasswordAuthenticator de couchbase.opções importação ClusterOptions de data e hora importação tempo decorrido autenticação = PasswordAuthenticator(nome de usuário do db, senha_db) opções = ClusterOptions(autenticação) connect_string = connection_string agrupamento = Aglomerado(connect_string, opções) # Aguarde até que o cluster esteja pronto para uso. agrupamento.wait_until_ready(tempo decorrido(segundos=5)) retorno agrupamento |
Com isso, temos uma conexão com o cluster do Couchbase e uma conexão com o wrapper do armazenamento vetorial do LangChain Couchbase.
connect_to_couchbase(connection_string, db_username, db_password) cria a conexão do cluster do Couchbase. get_vector_store(_cluster, db_bucket, db_scope, db_collection, _embedding, index_name,) cria o Armazém de vetor de sofá wrapper. Ele mantém uma conexão com o cluster, as informações de bucket/scope/collection para armazenar dados, o nome do índice para garantir que possamos consultar os vetores e a propriedade de incorporação.
Aqui, ele se refere à função OpenAIEmbeddings. Ela pegará automaticamente o OPENAI_API_KEY e permitir que a LangChain use a API da OpenAI com a chave. Cada chamada de API será transparente para a LangChain. O que também significa que a troca de provedor de modelo deve ser bastante transparente quando se trata de gerenciamento de incorporação.
Gravação de documentos LangChain no Couchbase
Agora é onde a mágica acontece, onde obtemos os tweets, os analisamos como JSON, criamos a incorporação e gravamos o documento JSON na coleção específica do Couchbase. Graças ao Steamlit, podemos configurar um widget de upload de arquivo e executar uma função associada:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
importação arquivo temporário importação os de langchain.loja de documentos.documento importação Documento def save_tweet_to_vector_store(arquivo carregado, vector_store): se arquivo carregado é não Nenhum: dados = json.carregar(arquivo carregado) # Analise o arquivo carregado em JSON, esperando uma matriz de objetos documentos = [] IDs = [] para tuíte em dados: # Para todos os tweets JSON texto = tuíte['texto'] full_text = tuíte['full_text'] id = tuíte['id'] # Crie o documento Langchain, com um campo de texto e metadados associados. se full_text é não Nenhum: doc = Documento(conteúdo_da_página=full_text, metadados=tuíte) mais: doc = Documento(conteúdo_da_página=texto, metadados=tuíte) documentos.anexar(doc) IDs.anexar(id) # Crie uma matriz semelhante para IDs de documentos do Couchbase; se não for fornecido, o uuid será gerado automaticamente vector_store.add_documents(documentos = documentos, IDs = IDs) # Armazene todos os documentos e incorporações st.informações(f"Tuítes e respostas carregados no armazenamento vetorial em documentos {len(docs)}") |
Ele se parece um pouco com o código da parte 1, exceto pelo fato de que toda a criação de incorporação é gerenciada de forma transparente pelo LangChain. O campo de texto será vetorizado e os metadados serão adicionados ao documento do Couchbase. Ele terá a seguinte aparência:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "texto": "@kelseyhightower SOCKS! Jogarei milhões de dólares na primeira empresa que me oferecer meias!\n\nImportante observar aqui: Eu não tenho milhões de dólares! \n\nAcho que posso ter um problema.", "embedding" (incorporação): [ -0.0006439118069540552, -0.021693240183757154, 0.026031888593037636, -0.020210755239867904, -0.003226784468532888, ....... -0.01691936794757287 ], "metadata": { "created_at": "Thu Apr 04 16:15:02 +0000 2024", "id": "1775920020377502191", "full_text": nulo, "texto": "@kelseyhightower SOCKS! Jogarei milhões de dólares na primeira empresa que me oferecer meias!\n\nImportante observar aqui: Eu não tenho milhões de dólares! \n\nAcho que posso ter um problema.", "lang": "en", "in_reply_to": "1775913633064894669", "quote_count": 1, "reply_count": 3, "favorite_count": 23, "view_count": "4658", "hashtags": [], "usuário": { "id": "4324751", "name" (nome): "Josh Long", "nome_da_tela": "starbuxman", "url ": "https://t.co/PrSomoWx53" } } |
De agora em diante, temos funções para gerenciar o upload de tweets, vetorizar os tweets e armazená-los no Couchbase. É hora de usar o Streamlit para criar o aplicativo real e gerenciar o fluxo de bate-papo. Vamos dividir essa função em vários blocos.
Escreva um aplicativo Streamlit
Começando com a declaração principal e a proteção do aplicativo. Você não quer que ninguém o use e use seus créditos do OpenAI. Graças ao Streamlit, isso pode ser feito com bastante facilidade. Aqui, configuramos uma proteção por senha usando o parâmetro LOGIN_PASSWORD variável env. E também definimos a configuração global da página graças à variável set_page_config método. Isso lhe dará um formulário simples para inserir a senha e uma página simples.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
se nome == "__main__": Autorização # se "auth" não em st.estado da sessão: st.estado da sessão.autenticação = Falso st.set_page_config( título_da_página="Bate-papo com exportação de tweets usando Langchain, Couchbase e OpenAI", ícone_de_página="🤖", layout="centralizado", initial_sidebar_state="auto", itens_do_menu=Nenhum, ) AUTH = os.getenv("LOGIN_PASSWORD") check_environment_variable("LOGIN_PASSWORD") Autenticação # user_pwd = st.entrada_de_texto("Digite a senha", tipo="senha") pwd_submit = st.botão("Enviar") se pwd_submit e user_pwd == AUTH: st.estado da sessão.autenticação = Verdadeiro elif pwd_submit e user_pwd != AUTH: st.erro("Senha incorreta") |
Para ir um pouco além, podemos adicionar as verificações de variáveis de ambiente, a configuração do OpenAI e do Couchbase e um título simples para iniciar o fluxo do aplicativo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
se st.estado da sessão.autenticação: # Carregar variáveis de ambiente DB_CONN_STR = os.getenv("DB_CONN_STR") NOME DE USUÁRIO DO BANCO = os.getenv("DB_USERNAME") DB_PASSWORD = os.getenv("DB_PASSWORD") DB_BUCKET = os.getenv("DB_BUCKET") DB_SCOPE = os.getenv("DB_SCOPE") DB_COLLECTION = os.getenv("DB_COLLECTION") INDEX_NAME = os.getenv("INDEX_NAME") # Certifique-se de que todas as variáveis de ambiente estejam definidas check_environment_variable("OPENAI_API_KEY") check_environment_variable("DB_CONN_STR") check_environment_variable("DB_USERNAME") check_environment_variable("DB_PASSWORD") check_environment_variable("DB_BUCKET") check_environment_variable("DB_SCOPE") check_environment_variable("DB_COLLECTION") check_environment_variable("INDEX_NAME") # Usar incorporações da OpenAI incorporação = OpenAIEmbeddings() # Conectar-se ao Couchbase Vector Store agrupamento = connect_to_couchbase(DB_CONN_STR, NOME DE USUÁRIO DO BANCO, DB_PASSWORD) vector_store = get_vector_store( agrupamento, DB_BUCKET, DB_SCOPE, DB_COLLECTION, incorporação, INDEX_NAME, ) st.título("Bate-papo com X") |
O Streamlit tem uma boa integração de espaço de código. Eu realmente recomendo que você o use, pois facilita muito o desenvolvimento. E nosso plug-in VSCode pode ser instalado, para que você possa navegar no Couchbase e executar consultas.
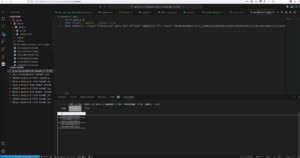
Executar a consulta SQL++ Vector Search do Codespace
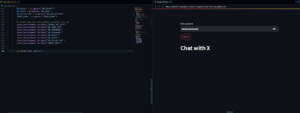
Um aplicativo Basic Streamlit aberto no Codespace
Criar cadeias LangChain
Depois disso, vem a configuração da corrente. É aí que o LangChain realmente se destaca. É aqui que podemos configurar o retriever. Ele será usado pelo LangChain para consultar o Couchbase em busca de todos os tweets vetorizados. Em seguida, é hora de criar o prompt do RAG. Você pode ver que o modelo usa um {contexto} e {pergunta} parâmetro. Criamos um objeto de prompt de chat a partir do modelo.
Depois disso, vem a escolha do LLM, aqui escolhi o GPT4. E, finalmente, a criação da cadeia.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Use o armazenamento de vetores do couchbase como um retriever para o RAG retriever = vector_store.as_retriever() # Crie o prompt para o RAG modelo = """Você é um bot útil. Se você não puder responder com base no contexto fornecido, responda com uma resposta genérica. Responda à pergunta da forma mais verdadeira possível usando o contexto abaixo: {contexto} Pergunta: {question}"""" imediato = ChatPromptTemplate.from_template(modelo) # Usar o OpenAI GPT 4 como LLM para o RAG lm = ChatOpenAI(temperatura=0, modelo="gpt-4-1106-preview", transmissão=Verdadeiro) Corrente # RAG cadeia = ( {"contexto": retriever, "pergunta": RunnablePassthrough()} | imediato | lm | StrOutputParser() ) |
A cadeia é criada a partir do modelo escolhido, do contexto e dos parâmetros de consulta, do objeto de prompt e de um StrOuptutParser. Sua função é analisar a resposta do LLM e enviá-la de volta como uma cadeia de caracteres streamable/chunkable. A função RunnablePassthrough chamado para o parâmetro da pergunta é usado para garantir que ele seja passado para o prompt "como está", mas você pode usar outros métodos para alterar/sanitizar a pergunta. É isso, uma arquitetura RAG. Fornecer algum contexto adicional a um prompt do LLM para obter uma resposta melhor.
Também podemos construir uma cadeia sem ela para comparar os resultados:
|
1 2 3 4 5 6 7 8 9 10 11 |
# Saída OpenAI pura sem RAG template_without_rag = """Você é um bot útil. Responda à pergunta da forma mais verdadeira possível. Question: {question}""" prompt_without_rag = ChatPromptTemplate.from_template(template_without_rag) llm_without_rag = ChatOpenAI(modelo="gpt-4-1106-preview") chain_without_rag = ( {"pergunta": RunnablePassthrough()} | prompt_without_rag | llm_without_rag | StrOutputParser() ) |
Não há necessidade de contexto no modelo de prompt e no parâmetro de cadeia, e não há necessidade de um retriever.
Agora que temos algumas cadeias, podemos usá-las por meio do Streamlit. Esse código adicionará a primeira pergunta e a barra lateral, permitindo upload de arquivos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
Front-end do # logotipo da couchbase = ( "https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png" ) st.remarcação para baixo( "As respostas com [logotipo do Couchbase] (https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png) são geradas usando RAG, enquanto 🤖 são geradas por LLM puro (ChatGPT)" ) com st.barra lateral: st.cabeçalho("Faça upload de seu X") com st.formulário("upload X"): arquivo carregado = st.carregador de arquivos( "Escolha uma exportação X.", ajuda="O documento será excluído após uma hora de inatividade (TTL).", tipo="json", ) apresentado = st.botão form_submit_button("Upload") se apresentado: # armazena os tweets no armazenamento de vetores save_tweet_to_vector_store(arquivo carregado, vector_store) st.subtítulo("Como isso funciona?") st.remarcação para baixo( """ Para cada pergunta, você terá duas respostas: * um usando RAG ([logotipo do Couchbase](https://emoji.slack-edge.com/T024FJS4M/couchbase/4a361e948b15ed91.png)) * um que usa LLM puro - OpenAI (🤖). """ ) st.remarcação para baixo( "Para o RAG, estamos usando [Langchain] (https://langchain.com/), [Couchbase Vector Search] (https://couchbase.com/) e [OpenAI] (https://openai.com/). Buscamos tweets relevantes para a pergunta usando o Vector Search e os adicionamos como contexto ao LLM. O LLM é instruído a responder com base no contexto do Vector Store." ) # Ver código se st.caixa de seleção("Exibir código"): st.escrever( "Veja o código aqui: [Github](https://github.com/couchbase-examples/rag-demo/blob/main/chat_with_x.py)" ) |
Em seguida, as instruções e a lógica de entrada:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
# Examine o histórico de mensagens e acrescente a primeira mensagem, se estiver vazia se "mensagens" não em st.estado da sessão: st.estado da sessão.mensagens = [] st.estado da sessão.mensagens.anexar( { "função": "assistente", "content" (conteúdo): "Olá, sou um chatbot que pode conversar com os tweets. Como posso ajudá-lo?", "avatar": "🤖", } ) # Exibir mensagens de bate-papo do histórico na reexecução do aplicativo para mensagem em st.estado da sessão.mensagens: com st.chat_message(mensagem["função"], avatar=mensagem["avatar"]): st.remarcação para baixo(mensagem["content" (conteúdo)]) # Reagir à entrada do usuário se pergunta := st.entrada_de_chat("Faça uma pergunta com base nos Tweets"): # Exibir mensagem do usuário no contêiner de mensagens do bate-papo st.chat_message("usuário").remarcação para baixo(pergunta) # Adicionar mensagem do usuário ao histórico do bate-papo st.estado da sessão.mensagens.anexar( {"função": "usuário", "content" (conteúdo): pergunta, "avatar": "👤"} ) # Adicionar espaço reservado para transmitir a resposta com st.chat_message("assistente", avatar=logotipo da couchbase): message_placeholder = st.vazio() # transmitir a resposta do RAG rag_response = "" para pedaço em cadeia.fluxo(pergunta): rag_response += pedaço message_placeholder.remarcação para baixo(rag_response + "▌") message_placeholder.remarcação para baixo(rag_response) st.estado da sessão.mensagens.anexar( { "função": "assistente", "content" (conteúdo): rag_response, "avatar": logotipo da couchbase, } ) # transmite a resposta do LLM puro # Adicionar espaço reservado para transmitir a resposta com st.chat_message("ai", avatar="🤖"): message_placeholder_pure_llm = st.vazio() pure_llm_response = "" para pedaço em chain_without_rag.fluxo(pergunta): pure_llm_response += pedaço message_placeholder_pure_llm.remarcação para baixo(pure_llm_response + "▌") message_placeholder_pure_llm.remarcação para baixo(pure_llm_response) st.estado da sessão.mensagens.anexar( { "função": "assistente", "content" (conteúdo): pure_llm_response, "avatar": "🤖", } ) |
Com isso, você tem tudo o que é necessário para executar o aplicativo streamlit que permite ao usuário:
-
- Faça upload de um arquivo JSON contendo tweets
- Transforme cada tweet em um documento LangChain
- Armazene-os no Couchbase junto com sua representação de incorporação
- Gerencie dois prompts diferentes:
- um com um recuperador LangChain para adicionar contexto
- e um sem
Se você executar o aplicativo, verá algo parecido com isto:

O exemplo completo do aplicativo streamlit foi aberto no Codespace
Conclusão
E quando você pergunta "as meias são importantes para os desenvolvedores?", obtém essas duas respostas muito interessantes:
Com base no contexto fornecido, parece que as meias são importantes para alguns desenvolvedores, conforme mencionado por Josh Long e Simon Willison em seus tweets. Eles expressam o desejo de usar meias e parecem valorizá-las.
As meias são importantes para os desenvolvedores, pois proporcionam conforto e suporte quando passam longas horas sentados em um computador. Além disso, manter os pés aquecidos pode ajudar a melhorar o foco e a produtividade.
Voilà, temos um bot que sabe sobre um tópico do Twitter e pode responder de acordo. E o mais divertido é que ele não usou apenas o texto Vector no contexto, mas também usou todos os metadados armazenados, como o nome de usuário, porque também indexamos todos os metadados do documento LangChain ao criar o índice na parte 1.
Mas isso está realmente resumindo o tópico X? Na verdade, não. Porque o Vector Search enriquecerá o contexto com os documentos mais próximos e não com o tópico completo. Portanto, é preciso fazer um pouco de engenharia de dados. Vamos falar sobre isso na próxima parte!
Recursos
-
- Obter o Exemplo de código de demonstração do RAG para acompanhar
- Inscreva-se em um teste gratuito do Couchbase Capella DBaaS para experimentar você mesmo