Hoje, temos o prazer de anunciar nossa nova integração com o NVIDIA NIM/NeMo. Nesta postagem do blog, apresentamos um conceito de solução de um chatbot interativo baseado em um Recuperação Geração aumentada (RAG) com o Couchbase Capella como um banco de dados vetorial. As fases de recuperação e geração do pipeline RAG são aceleradas pelo NVIDIA NIM/NeMo com apenas algumas linhas de código.
Empresas de vários setores verticais se esforçam para oferecer o melhor atendimento aos seus clientes. Para conseguir isso, elas estão equipando seus funcionários da linha de frente, como enfermeiros de emergência, vendedores de lojas e representantes de help desk, com chatbots interativos de perguntas e respostas (QA) com tecnologia de IA para recuperar rapidamente informações relevantes e atualizadas.
Os chatbots geralmente são baseados em RAGO LLM é uma estrutura de IA usada para recuperar fatos da base de conhecimento da empresa para fundamentar as respostas do LLM nas informações mais precisas e recentes. Ela envolve três fases distintas, que começam com a recuperação do contexto mais relevante usando pesquisa vetorialA consulta do usuário pode ser aumentada com o contexto e, por fim, gerar respostas relevantes usando um LLM.
O problema com os pipelines de RAG existentes é que as chamadas para o serviço de incorporação na fase de recuperação para converter os prompts do usuário em vetores podem adicionar uma latência significativa, tornando mais lentos os aplicativos que exigem interatividade. A vetorização de um corpus de documentos que consiste em milhões de PDFs, documentos e outras bases de conhecimento pode levar muito tempo para ser vetorizada, aumentando a probabilidade de uso de dados obsoletos para o RAG. Além disso, os usuários acham difícil acelerar a inferência (tokens/seg.) de forma econômica para reduzir o tempo de resposta dos aplicativos de chatbot.
A Figura 1 mostra uma pilha de desempenho que permitirá que você desenvolva facilmente um chatbot interativo de atendimento ao cliente. Ele consiste na estrutura de aplicativos StreamLit, LangChain para orquestração, Couchbase Capella para indexação e pesquisa de vetores e NVIDIA NIM/NeMo para acelerar os estágios de recuperação e geração.
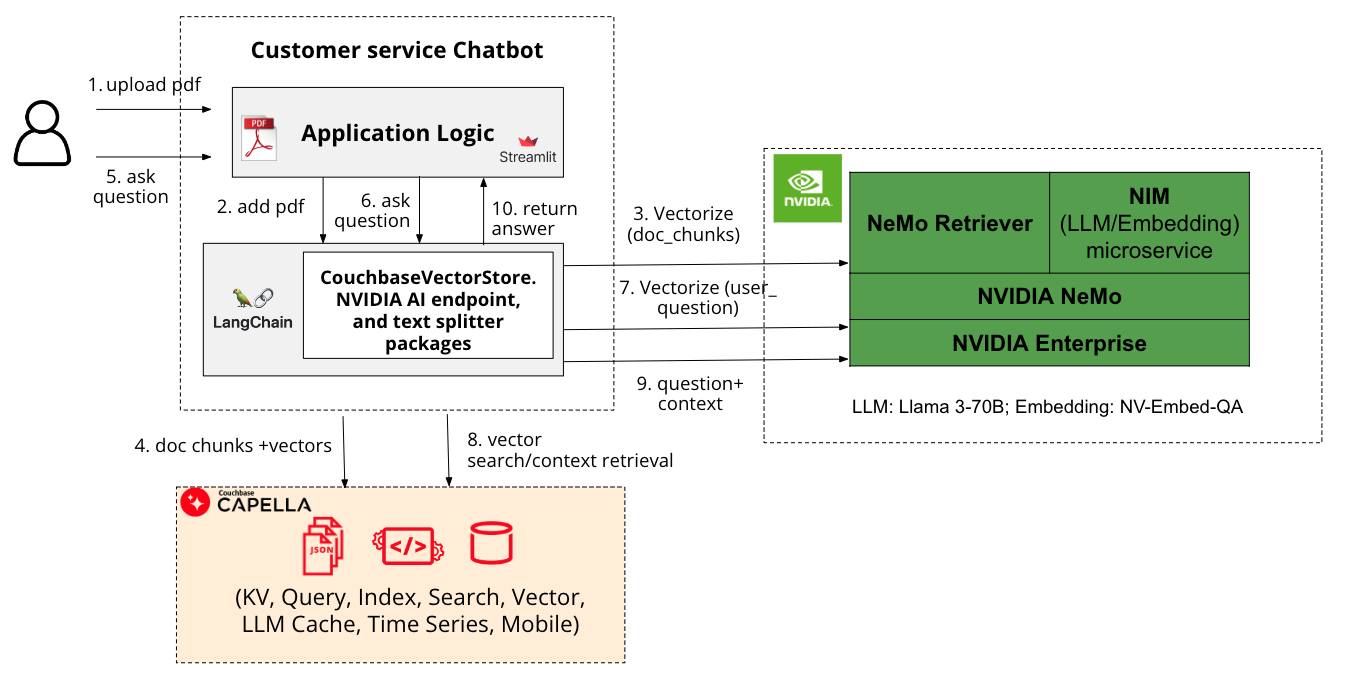
Figura 1: Arquitetura conceitual de um chatbot de controle de qualidade criado com o Capella e o NVIDIA NIM/NeMo
O Couchbase Capella, um banco de dados como serviço (DBaaS) de alto desempenho, permite que você comece rapidamente a armazenar, indexar e consultar dados operacionais, vetoriais, de texto, de séries temporais e geoespaciais, aproveitando a flexibilidade do JSON. Você pode integrar facilmente o Capella para pesquisa vetorial ou pesquisa semântica sem a necessidade de um banco de dados vetorial separado, integrando uma estrutura de orquestração, como o LangChain ou LlamaIndex em seu pipeline RAG de produção. Ele oferece os seguintes recursos pesquisa híbrida que combina a pesquisa vetorial com a pesquisa tradicional para melhorar significativamente o desempenho da pesquisa. Além disso, você pode estender a pesquisa vetorial para a borda usando o Couchbase mobile para casos de uso de IA de borda.
Depois de configurar o Capella Vector Search, você pode continuar a escolher um modelo de desempenho na seção Catálogo de APIs da NVIDIAque oferece um amplo espectro de modelos de fundação que abrangem modelos de código aberto, fundação NVIDIA AI e modelos personalizados, otimizados para oferecer o melhor desempenho na infraestrutura acelerada da NVIDIA. Esses modelos são implantados como NVIDIA NIM no local ou na nuvem usando contêineres pré-construídos fáceis de usar por meio de um único comando. NeMo Retriever, uma parte do NVIDIA NeMo, oferece recuperação de informações com a menor latência, a maior taxa de transferência e a máxima privacidade de dados.
O chatbot que desenvolvemos usando a pilha mencionada acima permitirá que você carregue seus documentos PDF e faça perguntas de forma interativa. Ele usa NV-QA-Embedum modelo de incorporação de texto acelerado por GPU usado para recuperação de perguntas e respostas, e Lhama 3 - 70Bque é empacotado como um NIM e acelerado na infraestrutura da NVIDIA. O langchain-nvidia-ai-endpoints contém integrações LangChain para a criação de aplicativos com modelos no NVIDIA NIM. Embora tenhamos usado endpoints hospedados pela NVIDIA para fins de prototipagem, recomendamos que você considere o uso do NIM auto-hospedado, consultando o Documentação do NIM para implementações de produção.
Você pode usar essa solução para dar suporte a casos de uso que exigem recuperação rápida de informações, como:
-
- Permitir que os enfermeiros do pronto-socorro acelerem a triagem por meio do acesso rápido a informações relevantes sobre saúde para aliviar a superlotação, as longas esperas por atendimento e a baixa satisfação dos pacientes.
- Ajudar os agentes de atendimento ao cliente a descobrir rapidamente o conhecimento relevante por meio de um chatbot de base de conhecimento interno para reduzir o tempo de espera das chamadas. Isso não apenas ajudará a aumentar as pontuações de CSAT, mas também permitirá o gerenciamento de grandes volumes de chamadas.
- Ajudar os vendedores em uma loja a descobrir e recomendar rapidamente itens em um catálogo de produtos semelhantes à imagem ou à descrição do item solicitado por um comprador, mas que está atualmente fora de estoque (falta de estoque), para melhorar a experiência de compra.
Em conclusão, você pode desenvolver um aplicativo GenAI interativo, como um chatbot, com respostas fundamentadas e relevantes usando o RAG baseado no Couchbase Capella e acelerá-lo usando o NVIDIA NIM/NeMo. Essa combinação oferece escalabilidade, confiabilidade e facilidade de uso. Além de ser implementado junto com o Capella para uma experiência de DBaaS, o NIM/NeMo pode ser implementado com o Couchbase local ou autogerenciado em nuvens públicas dentro de sua VPC para casos de uso que tenham requisitos mais rigorosos de segurança e privacidade. Além disso, você pode usar Guardrails NeMo para controlar a saída do seu LLM em relação ao conteúdo que sua empresa considera questionável.
Os detalhes do aplicativo de chatbot podem ser encontrados no arquivo Couchbase Portal do desenvolvedor juntamente com o código completo. Por favor, inscreva-se para um Conta de avaliação Capella, gratuito Conta NVIDIA NIMe comece a desenvolver seu aplicativo GenAI.