Garantir um fluxo contínuo de dados é fundamental para a análise e a tomada de decisões eficazes. Atualmente, como os dados geralmente não são estruturados e são aninhados, a escolha do banco de dados desempenha um papel importante na otimização da eficiência do processamento e do desempenho da consulta.
Nesta postagem do blog, exploraremos o processo de ingestão de dados do MongoDB, um banco de dados NoSQL, no ClickHouse, um banco de dados relacional, e no Couchbase Capella Columnarum banco de dados analítico NoSQL. Vamos nos concentrar no pré-processamento necessário, na eficiência da consulta para uniões após a ingestão e em como cada um deles lida com alterações de dados em tempo real. Mostraremos como o Capella Columnar simplifica o trabalho com dados aninhados, facilitando o armazenamento e a consulta em comparação com as complexidades de bancos de dados relacionais como o ClickHouse.
TL;DR
O ClickHouse exige um pré-processamento extenso para a ingestão de dados devido à falta de aninhamento de dados, e a adição de novos campos pode exigir a criação de tabelas adicionais. Os dados de uma única coleção do MongoDB devem ser divididos em tabelas separadas, o que significa que são necessárias junções para consulta, o que pode exigir muitos recursos. Além disso, adicionar um novo campo aninhado em tempo real envolve a recriação de tabelas separadas e a atualização de esquemas, levando a possíveis interrupções no pipeline e exigindo intervenção manual. Em contrapartida, o Capella Columnar simplifica o processo ao não exigir o pré-processamento de dados aninhados. Ele permite a ingestão direta de coleções do MongoDB sem a necessidade de tabelas separadas ou uniões, e reflete automaticamente as alterações em tempo real, como a adição de novos campos aninhados, sem processamento adicional.
O que é Capella Columnar?
Antes de mergulhar nesta demonstração de migração, você pode querer assistir à nossa visão geral detalhada do vídeo Capella Columnar ou ler nosso anúncio recente que apresentam essa nova tecnologia que converge as cargas de trabalho analíticas operacionais e em tempo real:
Amostra de dados do MongoDB
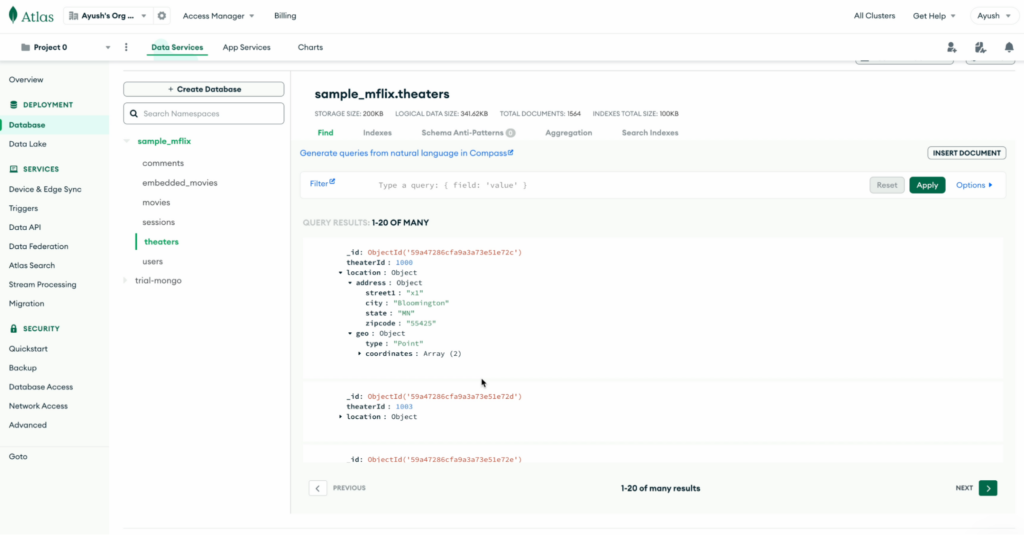
Para o escopo desta demonstração, usamos a coleção de amostra do MongoDB teatros do sample_mflix banco de dados.
Aqui está um exemplo de documento da coleção de teatros:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "_id": { "$oid": "59a47286cfa9a3a73e51e72c" }, "theaterId": 1000, "localização": { "endereço": { "street1": "x1", "cidade": "Bloomington", "estado": "MN", "zipcode" (código postal): "55425" }, "geo": { "tipo": "Ponto", "coordenadas": [ -93.24565, 44.85466 ] } } } |
Ingestão de dados do MongoDB para o Capella Columnar
Podemos utilizar o Kafka Links no Capella Columnar para ingerir dados dos tópicos do Kafka, onde os dados das coleções do MongoDB já foram publicados. Para que isso aconteça, os usuários precisam configurar o pipeline do Kafka, no qual os dados do MongoDB são canalizados para os tópicos do Kafka.
Etapa 1 - conectar o MongoDB ao Kafka
-
- Faça o download do Conector de origem do Debezium MongoDB
- Execute o Kafka Connect - no modo autônomo ou distribuído
- Envie uma solicitação POST com as propriedades de conexão necessárias para se conectar com
MongoDB
|
1 2 3 4 5 6 7 8 9 10 11 |
enrolar -X POST -H "Content-Type: application/json" http://localhost:8083/connectors -d '{"name": "", "config": { "connector.class": "io.debezium.connector.mongodb.MongoDbConnector", "capture.mode": "change_streams_update_full", "mongodb.ssl.enabled": "true" (verdadeiro), "topic.prefix": "", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "false" (falso), "key.converter.schemas.enable": "false" (falso), "key.converter": "org.apache.kafka.connect.json.JsonConverter", "collection.include.list": "sample_mflix.theaters", "mongodb.connection.string":<mongo conexão string>}}'¯ |
Substitua os espaços reservados na solicitação curl (indicados pelos colchetes angulares, por exemplo, <value>) com os valores apropriados para seu caso de uso específico.
Depois disso, seus dados encontrarão o caminho para o tópico do Kafka. Os dados estarão presentes no tópico do Confluent Kafka mongo_columnar_topic.sample_mflix.theaters:

Uma vez que os dados estejam no tópico do Kafka, agora podemos usar o Capella Columnar para extrair dados do tópico do Kafka para coleções.
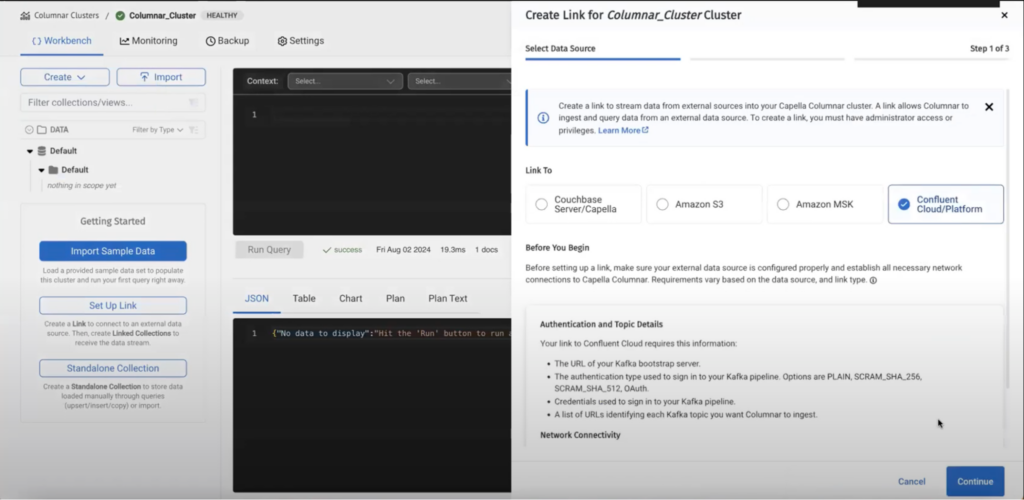
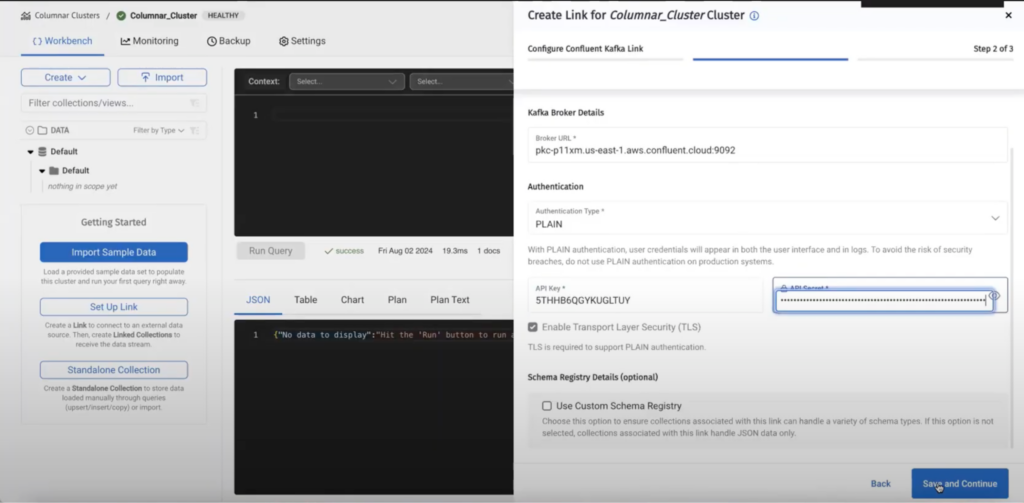
Etapa 2 - criar um link no Capella Columnar
Neste exemplo, estamos usando o Confluent Kafka como a variante do Kafka, mas o Capella Columnar também é compatível com o Amazon MSK.
Etapa 3 - criar uma coleção vinculada
Depois de criar um link, precisamos criar uma coleção vinculada na qual os dados serão armazenados:
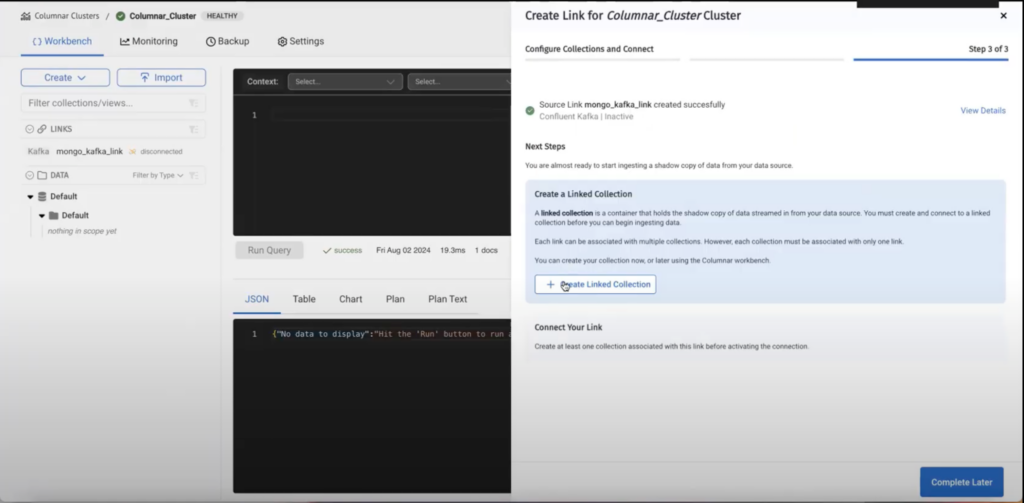
Os campos são autoexplicativos, o campo chave primária é o caminho da chave primária no documento do MongoDB que reside no tópico do Kafka. No exemplo dado, a chave primária do documento do MongoDB é objectId:
|
1 |
_id`$oid`: Cordas |
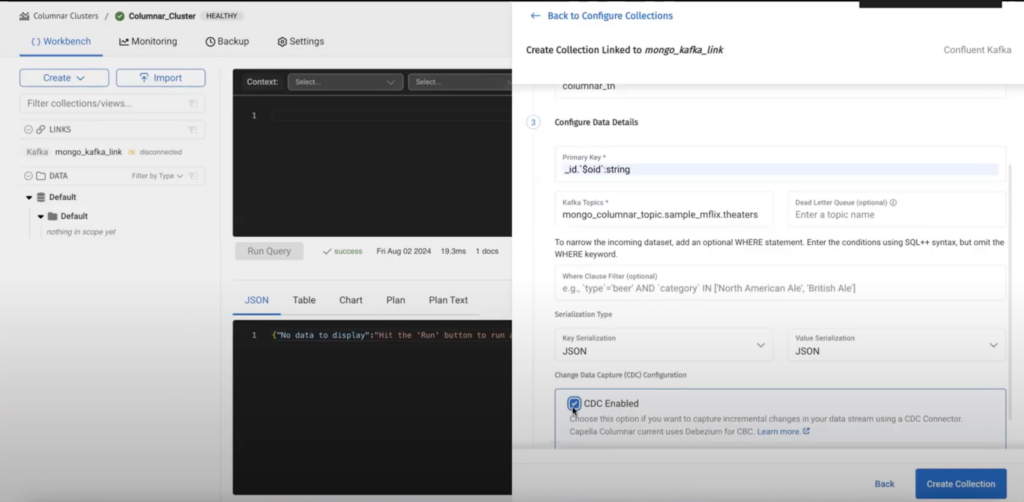
A ativação do CDC cria um acordo sobre o formato do documento que o mecanismo Capella Columnar entende. Atualmente, oferecemos suporte apenas ao Debezium como um conector de origem.
Etapa 4 - conectar o link
Depois de criar a coleção, temos que conectar o link.
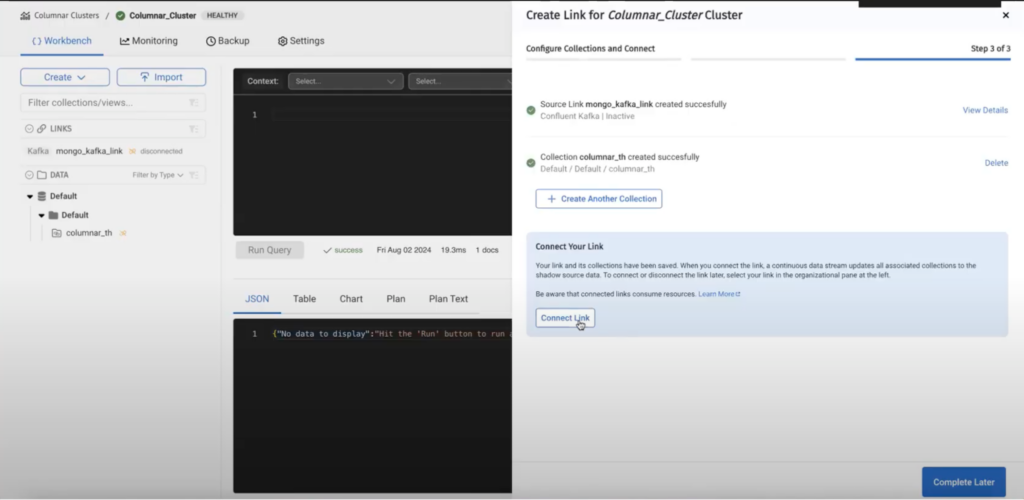
Uma vez que o link tenha sido conectado, os dados devem estar fluindo, como podemos ver na consulta abaixo.
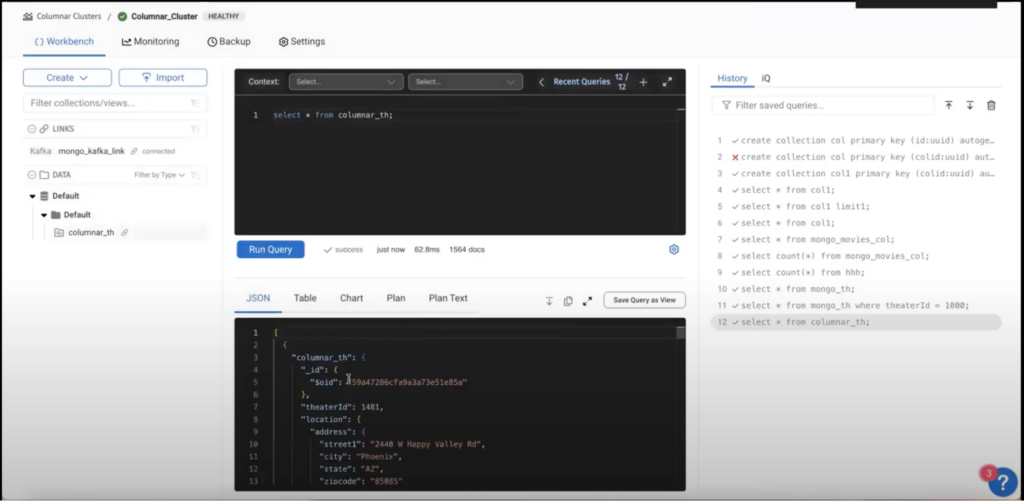
A ingestão de dados do MongoDB para o Capella Columnar foi perfeita e intuitiva. Agora, vamos voltar nossa atenção para os desafios que encontramos com bancos de dados relacionais como o ClickHouse.
Migração de dados do MongoDB para o ClickHouse
Como o ClickHouse é um banco de dados relacional, não podemos migrar dados diretamente do MongoDB devido às suas estruturas de dados aninhadas e baseadas em documentos. Isso requer uma etapa adicional de transformação de dados. A complexidade dessa transformação aumenta se os dados do MongoDB forem altamente aninhados ou se forem introduzidos campos adicionais, exigindo ajustes, como a criação de tabelas extras para gerenciar essas alterações.
Criação de uma tabela no ClickHouse para coleções do MongoDB
Para criar uma tabela no ClickHouse que mapeie para um MongoDB usamos a seguinte sintaxe:
|
1 2 3 4 5 6 |
CRIAR TABELA [IF NÃO EXISTE] [db.]nome_da_tabela ( nome1 [tipo1], nome2 [tipo2], ... ) MOTOR = MongoDB(hospedeiro:porto, banco de dados, coleção, usuário, senha [, opções]); |
A coleção do MongoDB referenciada aqui deve ser não aninhado antes de apontar para ele.
Temos um teatros no MongoDB, e nosso objetivo é representar esses dados em um formato relacional estruturado no ClickHouse.
Como o ClickHouse não oferece suporte a campos aninhados, precisaremos criar três tabelas para lidar com os campos teatros dados com esses esquemas:
-
- teatros: _id, theaterId
- endereço_de_localização_dos_teatros: Street1, cidade, estado, código postal
- teatros_localização_geo: tipo, coordenadas
Pré-processamento
Para preparar os dados, primeiro realizamos o pré-processamento no lado do MongoDB para aninhar os campos necessários. Isso envolve a criação de pipelines do MongoDB para extrair e achatar os campos aninhados em coleções separadas para Endereço e Geoenquanto o Teatros pode ser criada diretamente.
Pipelines para MongoDB Endereço coleção:
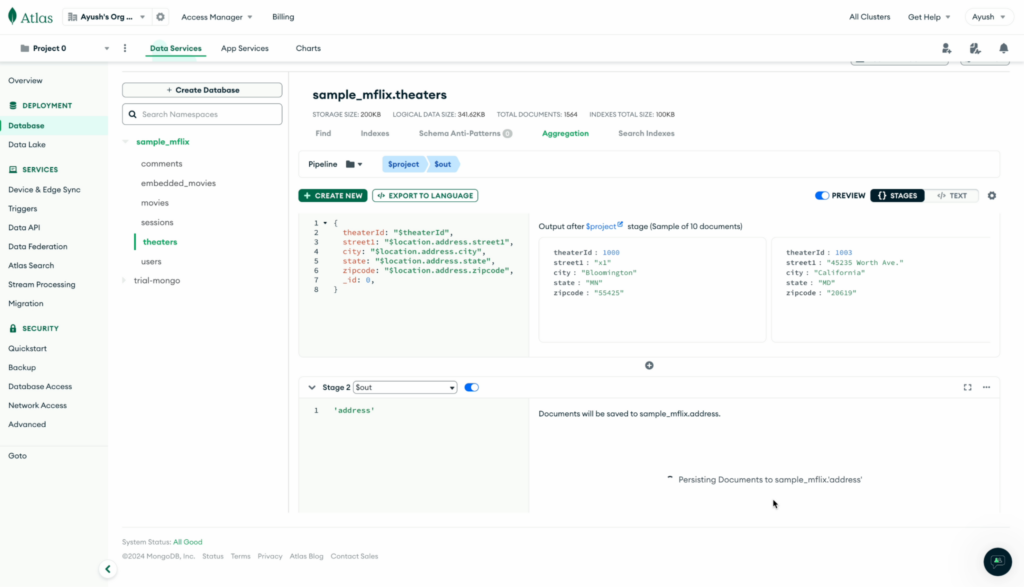
Pipeline para Geo coleção:
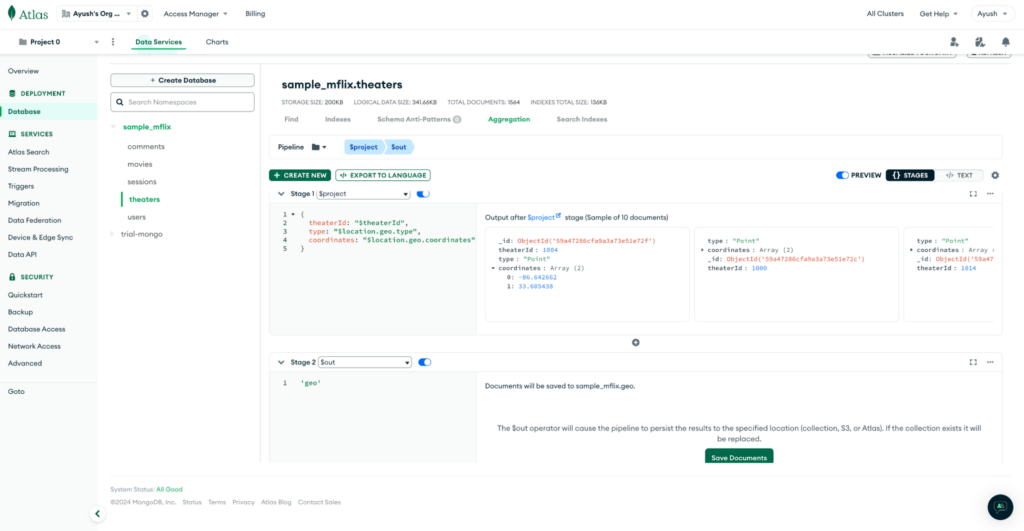
Criação de tabelas no ClickHouse
Após a conclusão do pré-processamento, criamos três tabelas correspondentes no ClickHouse:
Consulta para criar teatros:
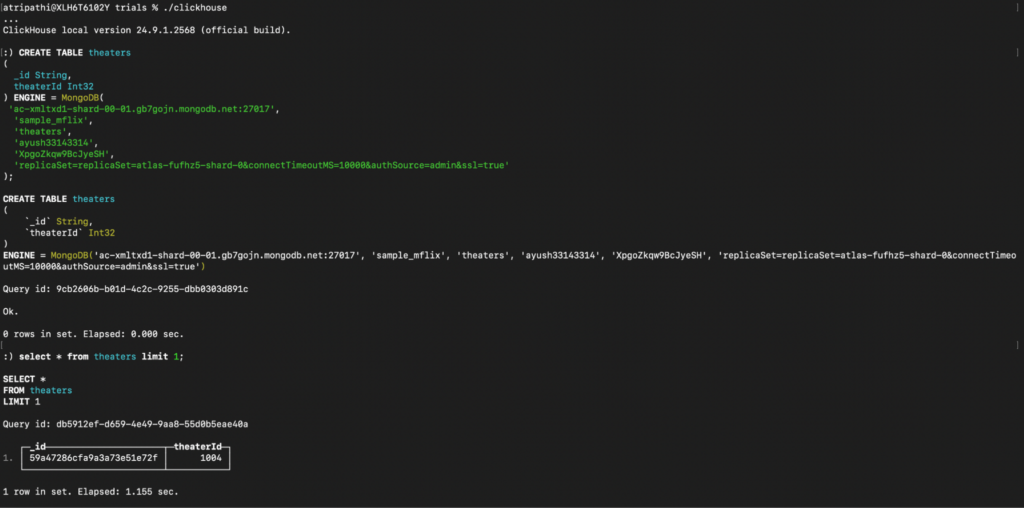
Consulta para criar theaters_location_address:
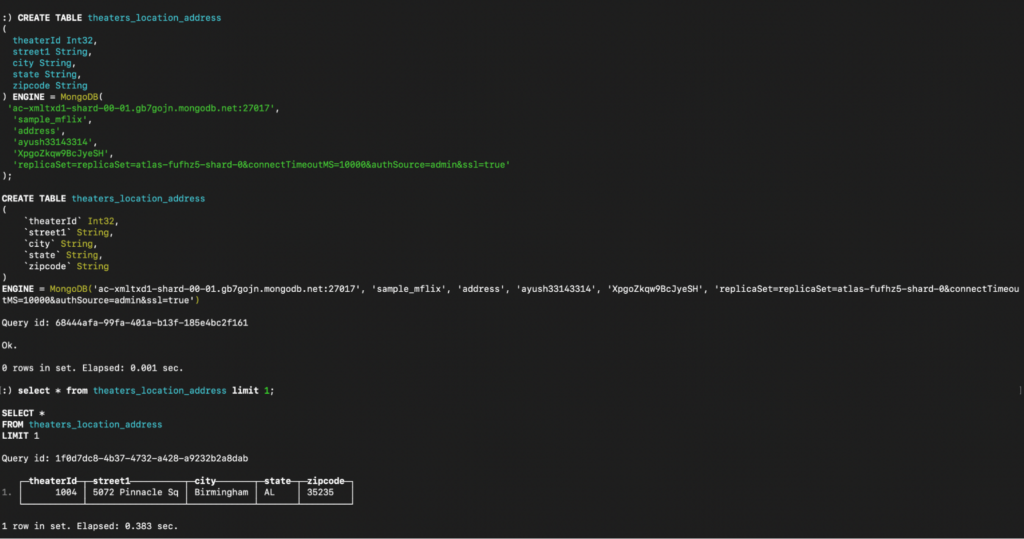
Consulta para criar teatros_localização_geo:
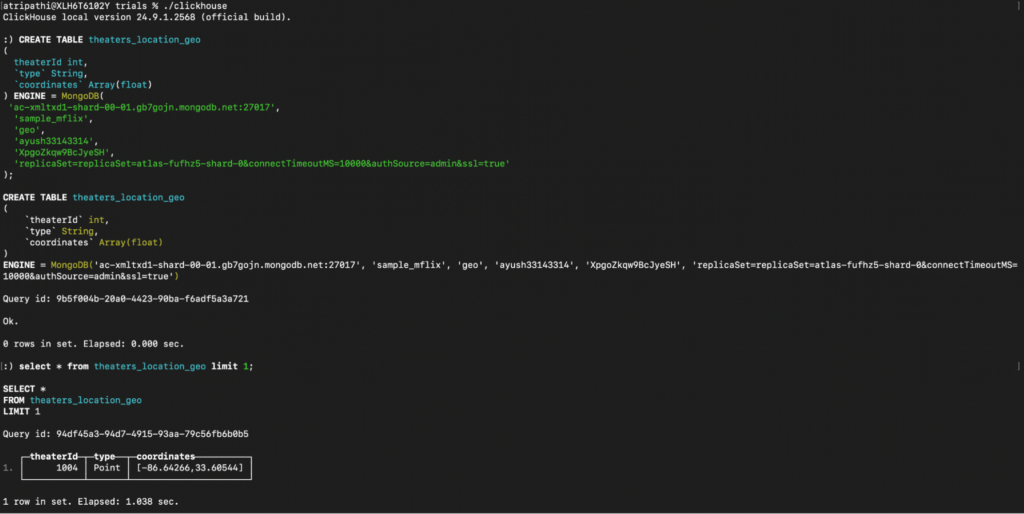
Depois de concluir a ingestão de dados do MongoDB para o ClickHouse, vamos explorar como as alterações de dados em tempo real são tratadas em ambos os sistemas. Examinaremos a facilidade de gerenciar essas alterações no Capella Columnar em comparação com os desafios enfrentados no ClickHouse.
Como as alterações em tempo real são tratadas?
Modificação no lado do MongoDB
Vamos alterar um documento no MongoDB e adicionar um campo proprietário aninhado.
|
1 2 3 4 5 6 |
{ "Proprietário": { "name" (nome): "John", "idade": 50 } } |
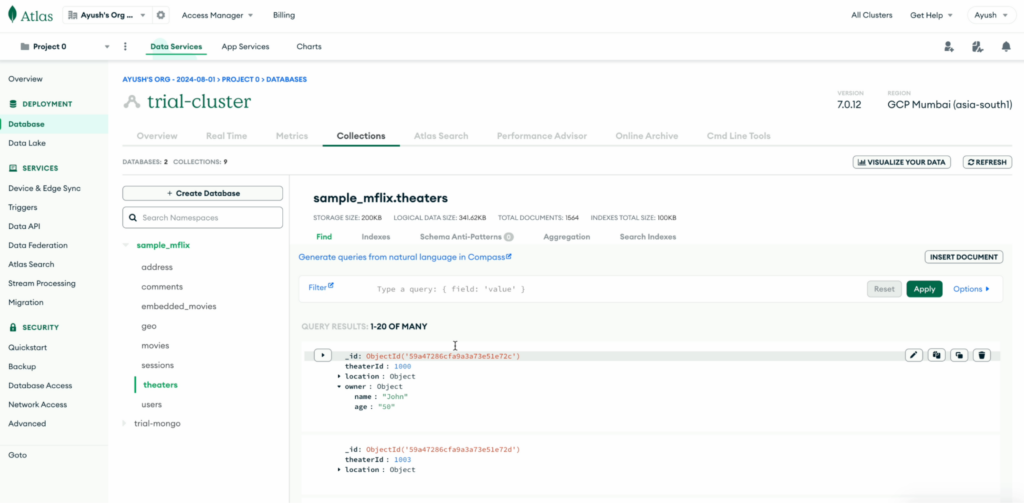
Alterações do Live CDC em Capella Columnar
Não é necessária nenhuma etapa adicional. Ao consultar o documento específico, podemos ver a alteração sendo refletida:
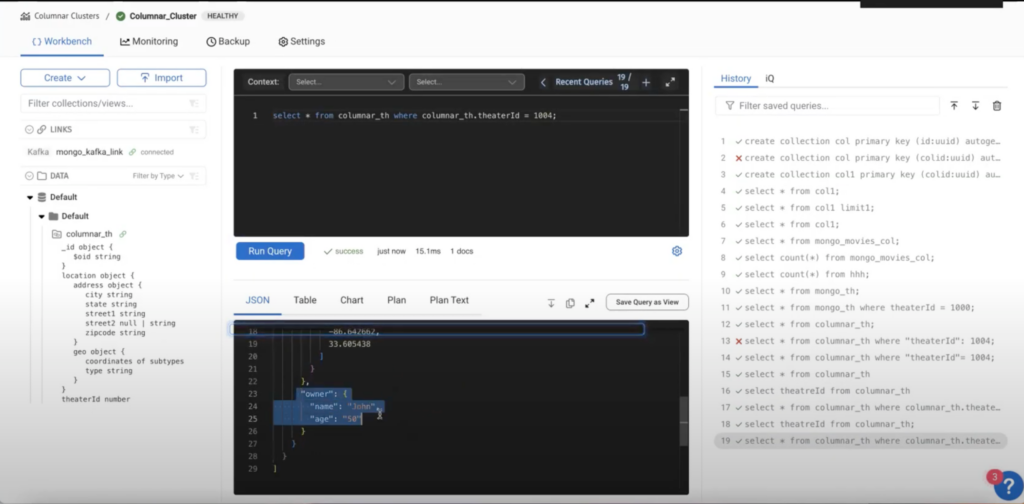
Configuração do ClickHouse
O ClickHouse enfrenta desafios para alterações em tempo real, pois o pipeline é interrompido quando se tenta fazer alterações diretamente.
Para buscar os dados atualizados que contêm o Proprietário você precisará criar outra tabela no ClickHouse. Primeiro, crie uma nova coleção do MongoDB em que o campo Proprietário não é aninhado e, em seguida, define uma tabela correspondente no ClickHouse.
Pipeline no MongoDB para criar uma coleção de proprietários:
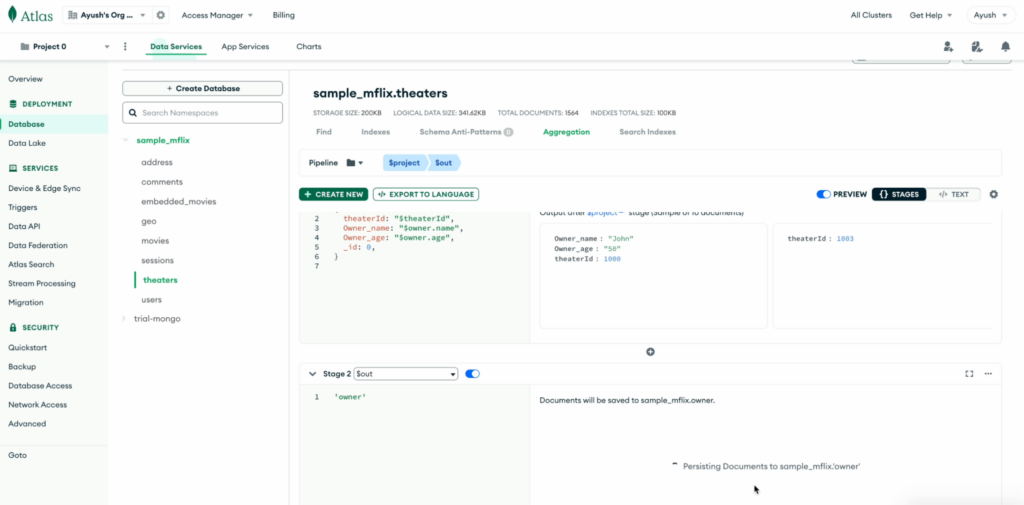
Criando o proprietário tabela no ClickHouse:
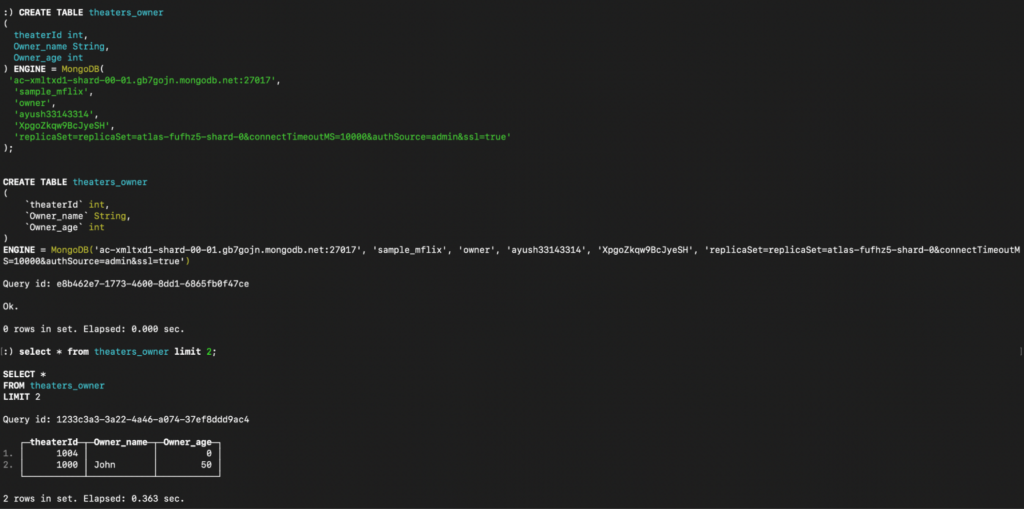
Agora, ao fazermos a transição para a consulta dos dados, é importante observar que, no ClickHouse, a execução até mesmo de consultas simples exige a junção dos dados, pois criamos tabelas diferentes para aninhar os dados originais. Em contrapartida, o Capella Columnar lida com essas consultas sem esforço, não exigindo etapas adicionais.
Consulta de dados no Capella Columnar vs. ClickHouse
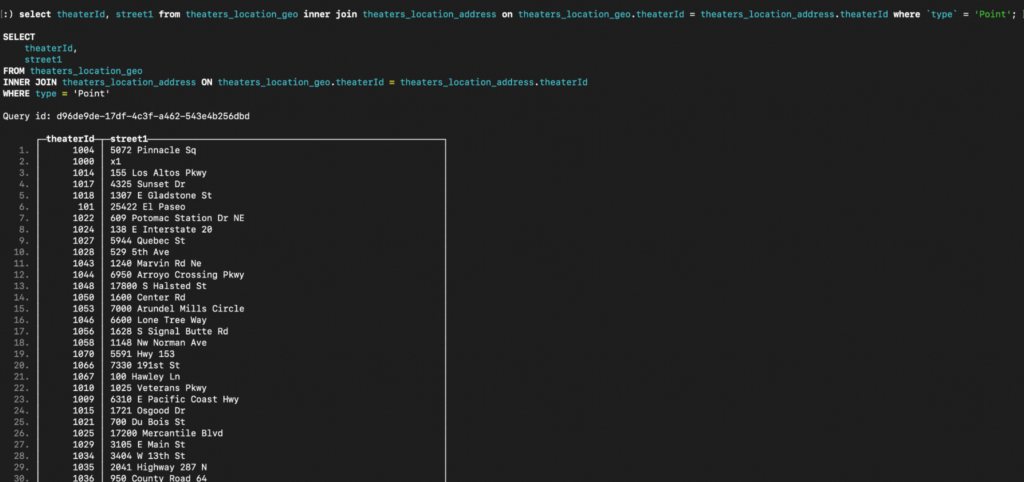
Vamos recuperar todos os theaterId e rua1 onde o geo tipo é Ponto na ClickHouse e na Capella Columnar.
Consulta para Capella Columnar:
|
1 |
selecionar theaterId, endereço.rua1 de colunar_th onde geo.tipo = "Ponto; |
Consulta para ClickHouse:
|
1 |
selecionar theaterId, rua1 de teatros_localização_geo interno unir-se endereço_de_localização_dos_teatros em teatros_localização_geo.theaterId = endereço_de_localização_dos_teatros.theaterId onde `tipo` = "Ponto; |
Comparação entre o ClickHouse e o Capella Columnar
| Parâmetro | ClickHouse | Capella Columnar |
| Ingestão de dados | É necessário um pré-processamento extenso devido ao aninhamento de dados aninhados, e a adição de campos em colunas pode exigir a criação de tabelas adicionais. | Não é necessário pré-processamento para dados aninhados. |
| Esquema e transformação de dados | Os dados de uma única coleção do MongoDB precisam ser divididos em tabelas separadas, com junções necessárias para consulta, o que pode ser caro. | Os dados podem ser ingeridos diretamente da coleção do MongoDB sem a necessidade de tabelas ou uniões separadas. |
| Alterações de dados em tempo real | A adição de um novo campo aninhado requer a recriação de tabelas separadas para aninhar os dados, exigindo atualizações de esquema e transformações potencialmente complexas.
Isso leva a interrupções no pipeline e exige intervenção manual. |
As alterações em tempo real, como a adição de um novo campo aninhado, são refletidas automaticamente sem processamento adicional. |
Conclusão
Em resumo, o Couchbase Capella oferece uma abordagem mais simplificada para a ingestão e consulta de dados aninhados do MongoDB, minimizando o pré-processamento e lidando facilmente com alterações em tempo real. Por outro lado, o ClickHouse exige extensa transformação de dados e ajustes de esquema, o que o torna menos eficiente para gerenciar estruturas complexas e aninhadas. Para ambientes que lidam com dados em tempo real e formatos aninhados, o Capella Columnar prova ser a opção mais flexível e eficiente.