Couchbase continues to lead the way in enabling high-performance data analytics with the introduction of SDKs for Capella Columnar, its cutting-edge analytical database, designed for real-time JSON analytics with zero ETL and options for operational write-back. For developers who need fast, reliable access to columnar databases, these SDKs provide seamless integration across multiple programming languages. Whether you’re building in Java, Python, or Node.js, the Capella Columnar SDKs allow you to leverage the advanced capabilities of Couchbase’s analytical database with minimal effort.
In this blog post, we’ll explore the key features, benefits, and use cases of the newly launched Capella Columnar SDKs—showing how they simplify data operations for developers working on data-intensive applications. We also show code examples to illustrate the simplicity and consistency of our approach.
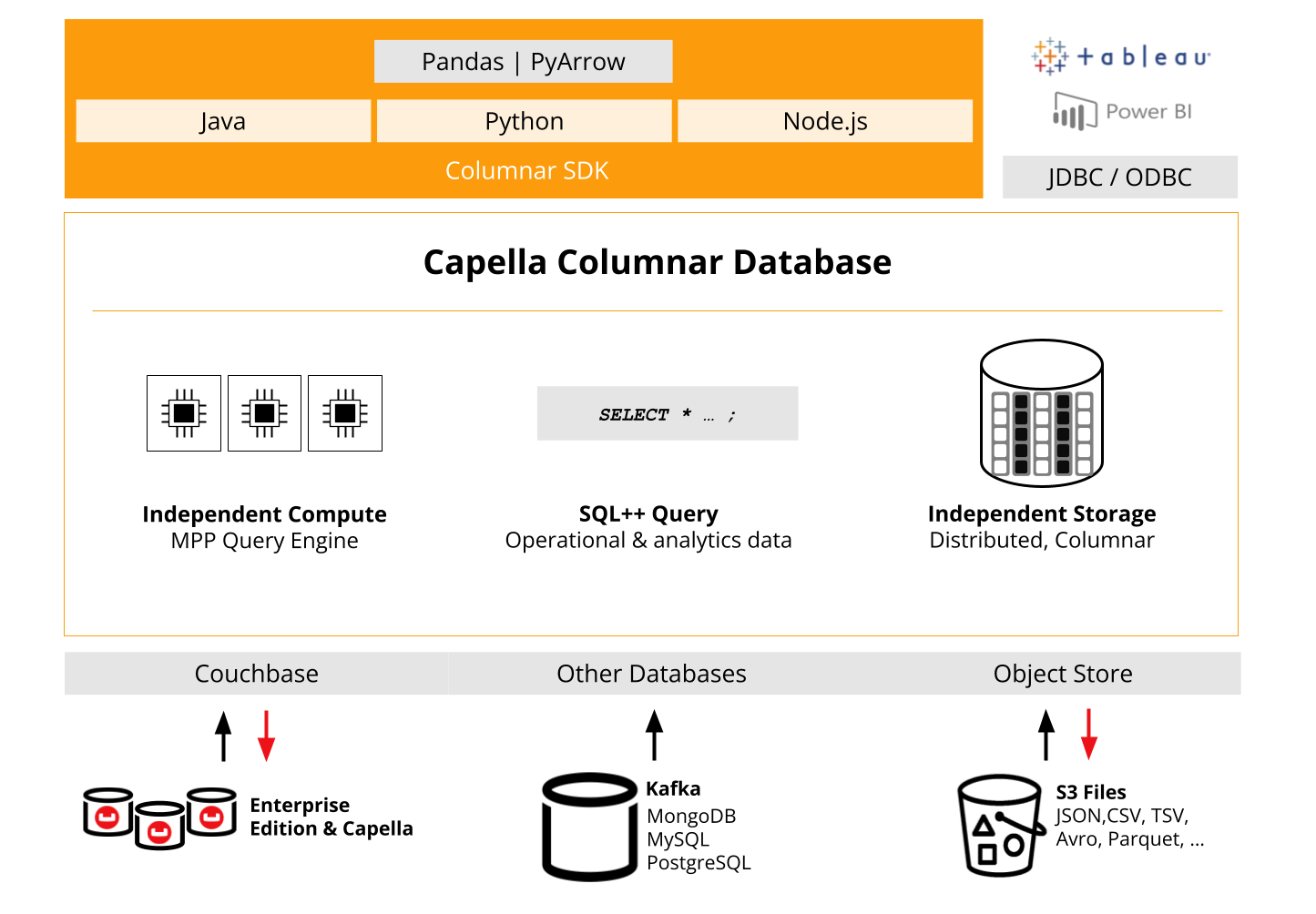
Purpose-built SDKs for real-time analytics
One of the core strengths of the Capella Columnar SDKs is their ability to optimize data access and query performance, making them ideal for large-scale analytical workloads. As organizations increasingly rely on real-time data analytics and batch processing, efficient querying and resource management become critical.
The Capella Columnar SDKs have been designed with these needs in mind, offering a range of features that help developers fine-tune data interactions and ensure high throughput, even under demanding conditions. The SDKs have been built from the ground up specifically for high performance and reliability by not taking shortcuts (such as wrappers over APIs, etc).
At the heart of the Capella Columnar SDKs are three core pillars:
- Ease of Development
Developers can interact with Couchbase’s columnar database within your existing tech stack without needing additional tools or configurations. The SDKs natively support each language, offering idiomatic APIs that feel natural to developers. - Discoverable APIs
The SDKs are designed with a fully discoverable API. This means that within your IDE, you’ll get automatic auto-completion and suggestions for functions, classes, and parameters, speeding up your development cycle. No more hunting for the right methods—the SDK will guide you as you build. - Robustness
Built with performance in mind, the SDKs provide advanced features like connection management, error handling, timeouts, and retries. These capabilities ensure your application remains stable even in high-load or fault-tolerant environments.
Platform and language support
The Capella Columnar SDKs support a diverse set of platforms and languages, including:
- Languages: Java (17+), Python (3.9-3.12), Node.js (v20, v22)
- Operating Systems: Linux, Windows, macOS (including support for ARM processors like AWS Graviton and Apple M1)
By offering support across these platforms, Couchbase ensures that developers can deploy their applications in diverse environments, from cloud infrastructures to on-premise systems.
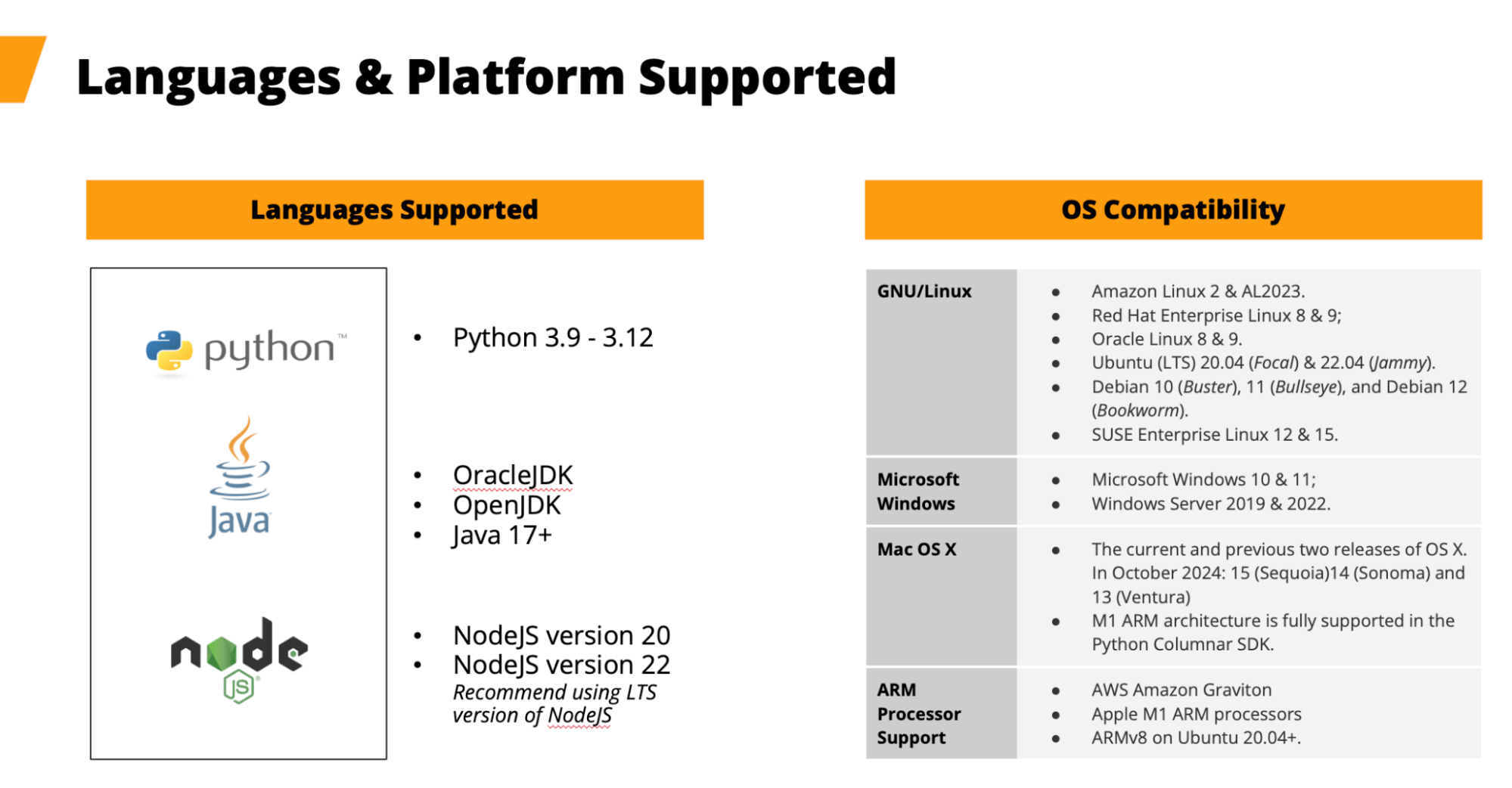
Figure 2. See the SDK documentation for any changes to language/platform support
Couchbase prioritizes future-proofing by maintaining backward compatibility across SDK versions, allowing developers to upgrade their applications without the fear of breaking changes. This commitment ensures that as new features and improvements are introduced, existing functionalities remain intact, enabling organizations to leverage the latest capabilities while preserving their established workflows.
How Capella Columnar SDKs help master data at scale
The Couchbase Capella Columnar SDKs offer a comprehensive toolset for managing large-scale data analytics efficiently, focusing on consistency, performance, and scalability.
Here’s an overview of the core features:
Unified API across languages
Capella Columnar SDKs provide a consistent API across languages like Java, Python, and Node.js, simplifying cross-team collaboration and allowing developers to switch between languages while maintaining a unified development experience.
Simplified data management and query execution
These SDKs offer intuitive access to scopes and collections, with support for both synchronous and asynchronous API calls. For query execution, they enable flexible SQL++ queries with options for Buffered Reads (for in-memory datasets) and Streaming Reads (for real-time processing of large datasets), optimizing performance based on operational needs.
Resilient connection management and error handling
The SDKs automatically adjust to database topology changes, ensuring smooth performance during failovers or rebalances. They also feature automatic query retries and provide clear error messages aligned with Couchbase’s Analytics Error Codes to aid in fast issue resolution.
Cross-Platform support and versioning flexibility
With support for multiple environments like Linux, Windows, MacOS, and ARM processors, the SDKs offer flexibility across infrastructures. Their versioned API framework ensures compatibility with new Couchbase features, allowing developers to integrate updates without compatibility concerns.
Scalability and distributed architecture
Capella Columnar SDKs leverage Couchbase’s distributed architecture for automatic data partitioning and Cross Data Center Replication (XDCR). This enables seamless scaling across multiple nodes and regions, ensuring high availability and efficient global data distribution as applications grow.
Use cases for Capella Columnar SDKs
Real-Time data analytics
For organizations handling real-time analytics, the Capella Columnar SDKs simplify data processing. With streaming query support, developers can process incoming data row-by-row, which is perfect for scenarios like log analysis, IoT sensor data, or real-time financial transactions.
Ad targeting example use case
A real-time analytics use case with Capella Columnar SDKs could involve integrating clickstream or web interaction data from, for example, an S3 bucket to drive just-in-time ad delivery. In this scenario, clickstream data, which captures real-time user interactions on a website, is streamed into Capella Columnar using external link configurations. The SDKs enable fast, efficient querying of this data as it arrives, using flexible SQL++ queries to analyze user behavior on the fly.
At the same time, user profile data stored in a NoSQL or relational database is fed into the system through Kafka connectors, allowing for a unified view of each user’s preferences and history. By combining these data streams with code used from Columnar SDKs, businesses can optimize their ad targeting strategy, delivering personalized ads based on the user’s latest interactions and historical preferences—all processed quickly and at scale using Capella Columnar’s distributed architecture.
Data science models could be applied using other tools, to find trends and build analytical results that drive appropriate experiences for the end user. This allows for timely, relevant ad delivery, maximizing engagement and conversion rates via applications built on the SDKs.
Batch data processing
For more traditional analytics workloads where data is processed in bulk, the buffered query mode ensures efficient memory usage while loading datasets into memory. Use cases like ETL processes, business intelligence, and data warehousing can benefit from this capability. Using the power of SQL++, BI tools can extract high value information quickly without needing to rely on as many 3rd party analytical tools.
Cross-language data operations
The unified API enables development teams to switch between programming languages easily without needing to learn new patterns. This is particularly useful for teams working on microservices architectures, where different components might be written in different languages (e.g., Java for backend services, Node.js for real-time APIs).
Technical overview: getting started
To give you a sense of how easy it is to get started with the all of the Capella Columnar SDKs, here’s an example of connecting to a Capella Columnar cluster using the Python SDK, see the docs for Java and Node.js examples:

Figure 3. Connection management code example in Python
The process is similar across all SDKs, ensuring a consistent experience regardless of the language. Once connected, you can execute SQL queries, manage scopes, and work with collections.
Asynchronous query execution
The Python SDK supports both Sync and Async Streaming APIs. Applications that need non-blocking operations can also perform asynchronous queries using Python’s asyncio framework. This allows you to run queries without waiting for them to finish, increasing throughput, especially when handling large datasets or slow operations. This example also shows buffered vs. streaming data access.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from acouchbase_columnar import get_event_loop from acouchbase_columnar.cluster import AsyncCluster query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM `travel-sample`.inventory.route GROUP BY airline ORDER BY route_count DESC """ res = await cluster.execute_query(query) # Buffered: Execute a query and buffer all result rows in client memory. all_rows = await res.get_all_rows() # NOTE: all_rows is a list, _do not_ use `async for` for row in all_rows: print(f'Found row: {row}') # Streaming: Execute a query and process rows as they arrive from server. res = await cluster.execute_query(statement) async for row in res.rows(): print(f'Found row: {row}') |
In this example, the asyncio event loop is used to handle queries asynchronously, allowing the application to perform other tasks while waiting for the query results.
Parameterized queries
Parameterized queries help protect your application from SQL injection attacks by separating query logic from data inputs. This is especially important when handling user-provided data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Positional Parameters query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM route WHERE sourceairport=$1 AND distance>=$2 GROUP BY airline ORDER BY route_count DESC """ res = scope.execute_query(query, QueryOptions(positional_parameters=['SFO', 1000])) # Named Parameters query = """ SELECT airline, COUNT(*) AS route_count, AVG(route.distance) AS avg_route_distance FROM route WHERE sourceairport=$source_airport AND distance>=$min_distance GROUP BY airline ORDER BY route_count DESC """ res = scope.execute_query(query, QueryOptions(named_parameters={'source_airport': 'SFO', 'min_distance': 1000})) |
In this example, we pass the airport code as a parameter, ensuring that the query remains safe and avoids the risks associated with SQL injection.
Using query results in data analytics libraries
Couchbase Columnar SDK integrates seamlessly with popular Python data analytics libraries like Pandas and PyArrow, common tools of choice for data science and AI/ML projects, making it easy to incorporate query results into your analytics workflow.
Importing query results into a Pandas DataFrame
This example shows how Couchbase query results can be easily converted into Pandas DataFrames, enabling data manipulation and exploration.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd res = scope.execute_query(query) df = pd.DataFrame.from_records(res.rows(), index='airline') print(df.head()) # airline route_count avg_route_distance # AA 2354 2314.884359 # UA 2180 2350.365407 # DL 1981 2350.494112 # US 1960 2101.417609 # WN 1146 1397.736500 |
Importing query results into a PyArrow Table
For performance-intensive tasks, Couchbase results can be used in PyArrow tables, facilitating in-memory analytics and integration with columnar storage systems.
|
1 2 3 4 5 6 7 8 9 10 |
import pyarrow as pa res = scope.execute_query(query) table = pa.Table.from_pylist(res.get_all_rows()) print(table.to_string()) # pyarrow.Table # route_count: int64 # avg_route_distance: double # airline: string |
By supporting both Pandas and PyArrow libraries, the Couchbase Columnar Python SDK simplifies integration into existing data science and data analytics pipelines, enabling efficient data analysis and processing.
These examples showcase how to execute buffered, streaming, asynchronous, and parameterized queries using Couchbase SDKs, allowing you to tailor query execution to your application’s requirements.
Conclusion
The Capella Columnar SDKs are a powerful addition for developers working with large-scale data analytics. With robust support for multiple languages, streamlined query execution, and cross-platform compatibility, these SDKs provide the flexibility, performance, and reliability needed to handle modern data workloads. Whether you’re processing real-time data streams or executing complex analytical queries, the Capella Columnar SDKs are designed to enhance your development experience.
Explore the possibilities and start building smarter, faster applications with Capella Columnar today!
Resources
-
- Documentation and install instructions: Python – Node.js – Java
- Learn more about Capella Columnar and its use cases
- Start using Capella, for free, today: sign up