 La búsqueda de texto completo se refiere a las técnicas de búsqueda de contenido textual dentro de un documento o una colección de documentos que contienen contenido textual. Un motor de búsqueda de texto completo examina todo el contenido textual de los documentos e intenta encontrar coincidencias con uno o varios términos de búsqueda.
La búsqueda de texto completo se refiere a las técnicas de búsqueda de contenido textual dentro de un documento o una colección de documentos que contienen contenido textual. Un motor de búsqueda de texto completo examina todo el contenido textual de los documentos e intenta encontrar coincidencias con uno o varios términos de búsqueda.
Probablemente haya oído hablar del motor de búsqueda de texto completo más conocido: Lucene con Elasticsearch construido sobre él. Couchbase Búsqueda de texto completo (FTS) Motor funciona con Blevey este artículo mostrará las distintas formas de analizar un texto dentro de este motor.
Bleve es una biblioteca de indexación y búsqueda de texto de código abierto implementada en Go y desarrollada internamente en Couchbase.
El motor FTS de Couchbase soporta índices que se suscriben a datos que residen dentro de un Servidor Couchbase e indexa los datos que recibe del servidor. Es un sistema distribuido, lo que significa que puede dividir los datos en varios nodos de un clúster y que las búsquedas implican la dispersión de la solicitud y la recopilación de respuestas de todos los nodos del clúster antes de responder a la aplicación.
El motor FTS distribuye los documentos ingeridos para un índice a través de un número configurable de particiones y estas particiones pueden residir en múltiples nodos dentro de un clúster. Cada partición sigue el mismo conjunto de reglas que el índice FTS para analizar e indexar el texto en la base de datos de búsqueda de texto completo.
En análisis de textos de un buscador de texto completo se encarga de descomponer el texto bruto en una lista de palabras, a las que llamaremos tokens. Estos tokens son más adecuados para indexarlos en la base de datos y realizar búsquedas.
El motor FTS de Couchbase se encarga de la indexación de texto para documentos JSON. Construye un índice para el contenido que se analiza y almacena en la base de datos - el índice junto con todos los metadatos relevantes necesarios para vincular los tokens generados a los documentos originales dentro de los cuales residen.
En Índice invertido es la estructura de datos elegida para indexar los tokens generados a partir del texto, con el fin de agilizar las consultas de búsqueda. Este índice relaciona cada token generado con los documentos que lo contienen.
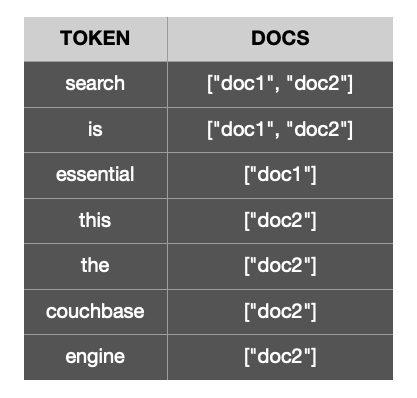
Por ejemplo, tome los siguientes documentos ..

El índice invertido para los tokens generados a partir de los 2 documentos anteriores se parecería a este..
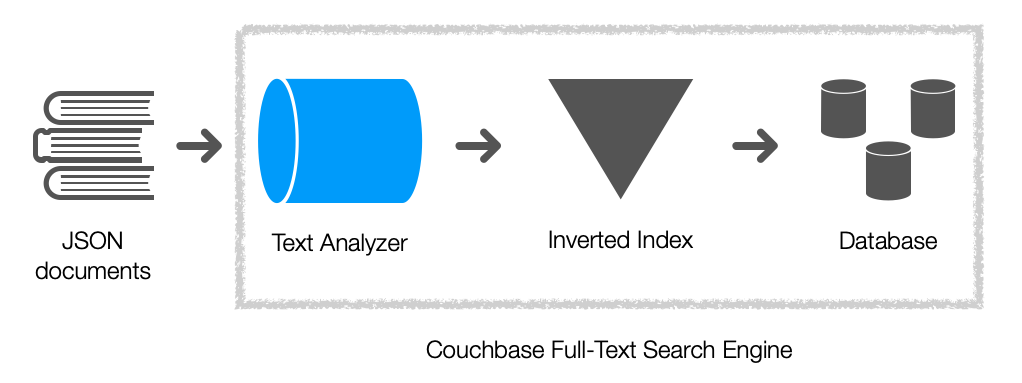
He aquí un diagrama en el que se destacan los componentes del motor de búsqueda de texto completo ...
Un analizador de textos
Los componentes de un analizador de texto pueden clasificarse a grandes rasgos en 2 categorías:
-
- Tokenizer
- Filtros
El motor de Couchbase clasifica además los filtros en:
-
- Filtros de caracteres
- Filtros de fichas
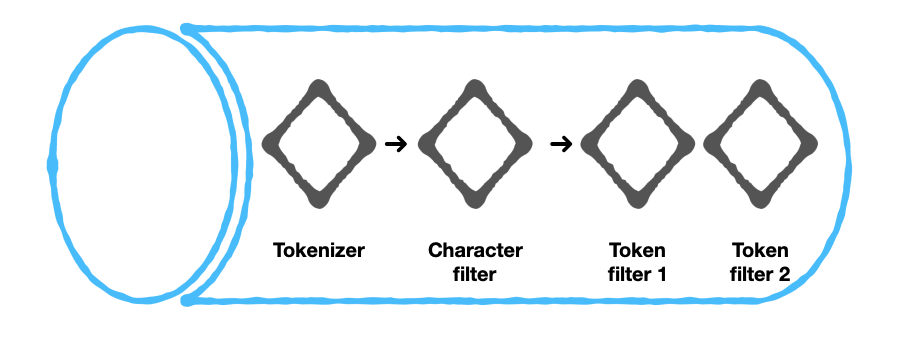
Antes de sumergirnos en la función de cada uno de estos componentes, he aquí una visión general de un analizador de texto...

Tokenizer
Un tokenizador es el primer componente al que se someten los documentos. Como su nombre indica, descompone el texto bruto en una lista de tokens. Esta conversión dependerá de un conjunto de reglas definidas para el tokenizador.
Tokenizadores de acciones ..
Tomemos como ejemplo este texto: "este es mi email ID: abhi123@cb.com"
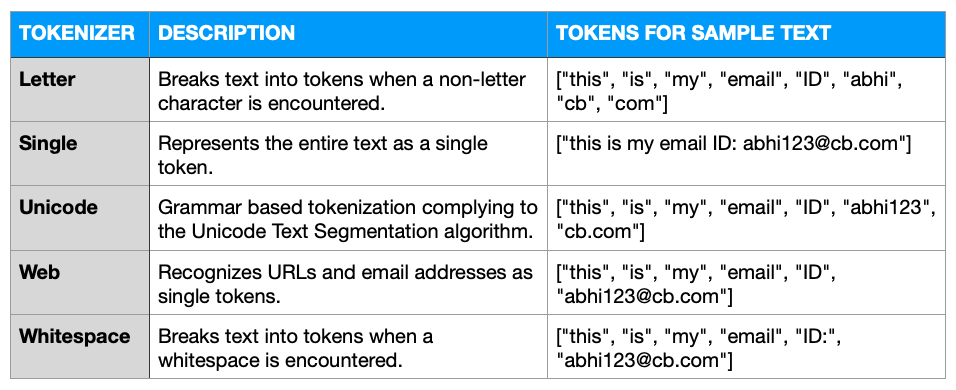
Un par de tokenizadores configurables ..
-
- Excepción .. Este tokenizador permite al usuario introducir patrones de excepción (expresiones regulares) sobre los tokenizadores habituales.
- Regexp .. Este tokenizador extrae el texto que coincide con el patrón (una expresión regular) como tokens.
Por ejemplo:

Filtro de caracteres
Los filtros de caracteres sirven para eliminar o sustituir caracteres no deseados.
Filtros de caracteres de stock ..

Un filtro de caracteres configurable ..
-
- Regexp .. Acepta una expresión regular válida y una cadena de sustitución para reemplazar el patrón coincidente.
Por ejemplo:

Filtro de fichas
Los filtros de tokens aceptan un flujo de tokens proporcionado por un tokenizador y realizan modificaciones en los tokens del flujo. Las formas más comunes de filtrado de tokens son la normalización y el stemming.
Varios filtros de fichas de valores, aquí están algunos destacados ..
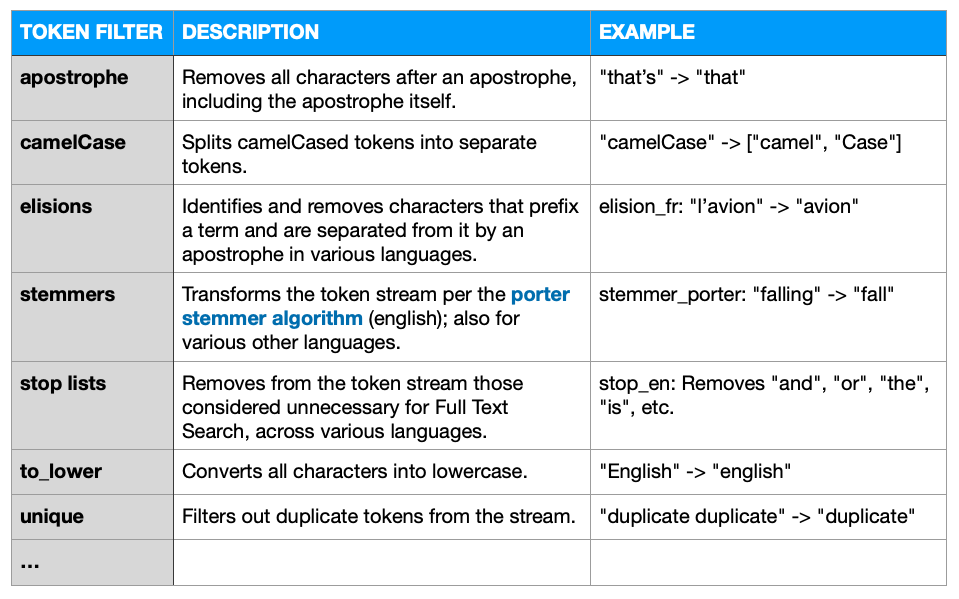
Filtros de fichas configurables ..
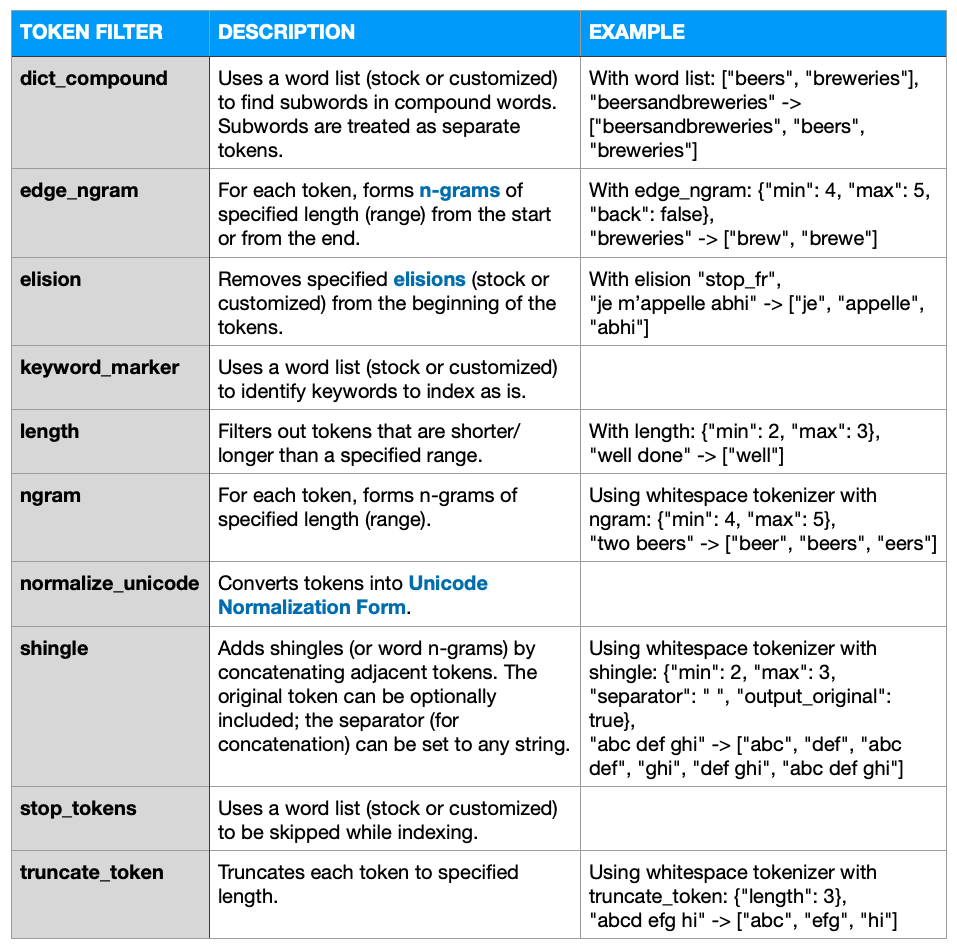
Analizadores de existencias
Con el motor de búsqueda de texto completo de Couchbase, los analizadores y todos sus componentes trabajan sobre el texto que constituye los valores de campo dentro de los documentos JSON. No trabajan sobre nombres de campo.
Considere el documento JSON:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "campo1": "valor1", "campo2": "valor2", "array_field3": [ "valor3", "valor4" ], "campo_objeto4": { "campo5": "valor5", "campo6": "valor6" } } |
Para el documento, se pueden definir analizadores que trabajen sobre "valor1", "valor2", "valor3", "valor4", "valor5" y "valor6".
Couchbase ofrece varios analizadores de valores ..

He aquí un par de ejemplos ..


Configuración de un analizador personalizado
- La clave para diseñar un analizador personalizado no es sólo elegir el tokenizador y los filtros adecuados, sino también aplicarlos en el orden correcto.
- Así pues, el primer paso sería configurar los tokenizadores, filtros de caracteres y filtros de tokens personalizados (junto con listas de palabras personalizadas) si fuera necesario.
- A continuación, cree el analizador eligiendo el tokenizador, los filtros de caracteres y los filtros de token deseados. Si has configurado alguno personalizado, aparecerá en la lista de opciones disponibles.
- El ORDEN de los filtros de caracteres y de tokens elegidos puede marcar la diferencia en la salida que se vea.
- Al seleccionar un valor de campo para indexar, elija el analizador deseado para él. De lo contrario, se heredará un analizador de la asignación principal. Las opciones personalizadas se mostrarán en la lista de opciones disponibles.
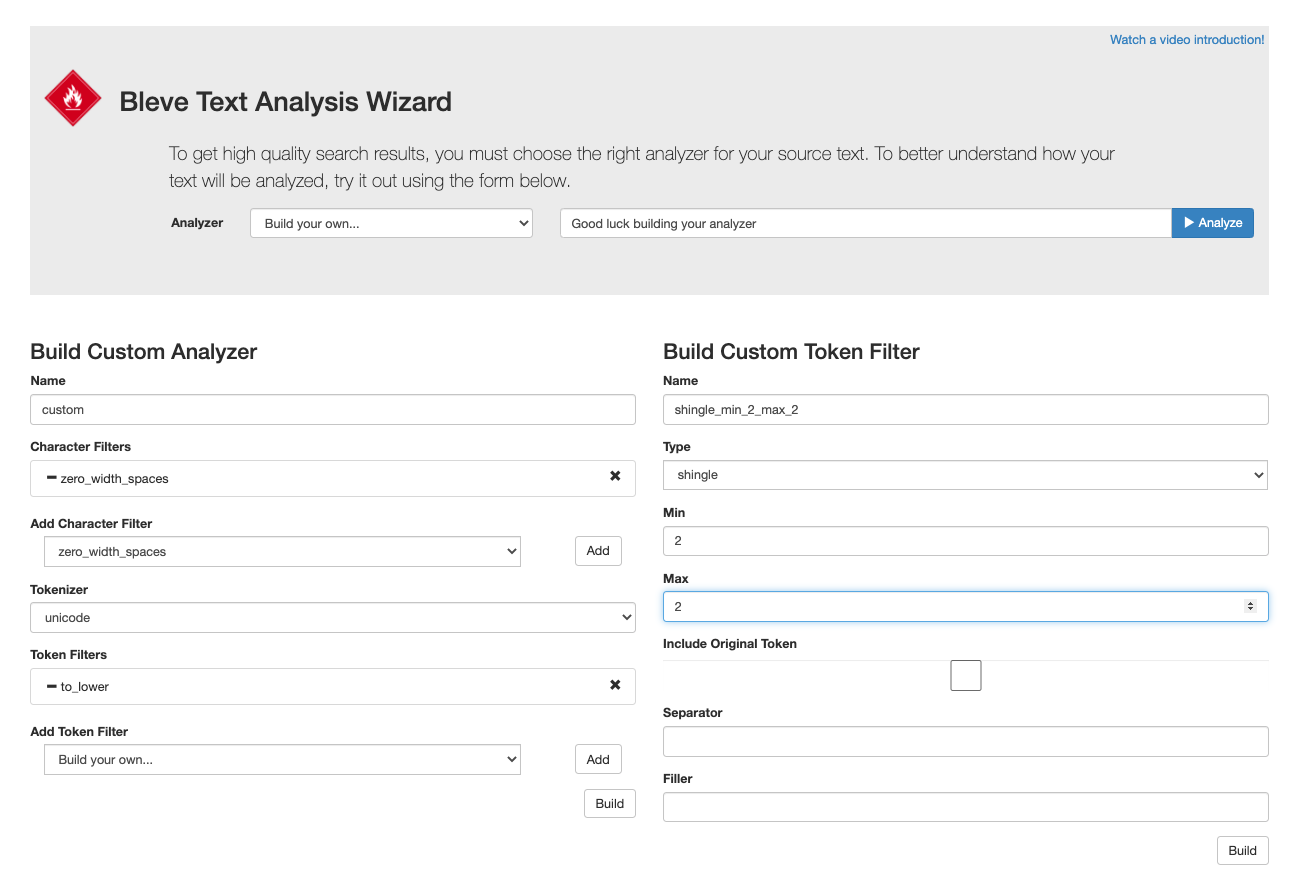
Campo de juego de análisis de textos
Pruebe el comportamiento de nuestros analizadores de stock y sus analizadores personalizados aquí ...
https://bleveanalysis.couchbase.com
Aquí hay una buena lectura sobre las mejores prácticas durante el uso de la búsqueda de texto completo de Couchbase ...
Mejores prácticas de indexación de búsquedas de texto completo por caso de uso