TLDR: A Couchbase anuncia novos serviços de IA na plataforma de dados do desenvolvedor Capella para criar e operar de forma eficiente e eficaz Agentes com tecnologia GenAI. Esses serviços incluem Serviço de modelo para hospedagem privada e segura de LLMs de código aberto, o Serviço de dados não estruturados para processar PDFs e imagens para ingestão, o Serviço de vetorização para streaming em tempo real, armazenamento e indexação de embeddings de vetores, um Catálogo de agentes fornecer uma estrutura extensível para ajudar os desenvolvedores a adicionar novos recursos à pilha de agentes, e Funções de IA para enriquecer os dados usando o poder dos LLMs, coletar os principais artefatos de dados gerados pelos agentes e estabelecer proteções para operações em evolução à medida que os LLMs e os agentes se desenvolvem.
Apresentando os Serviços de IA da Capella
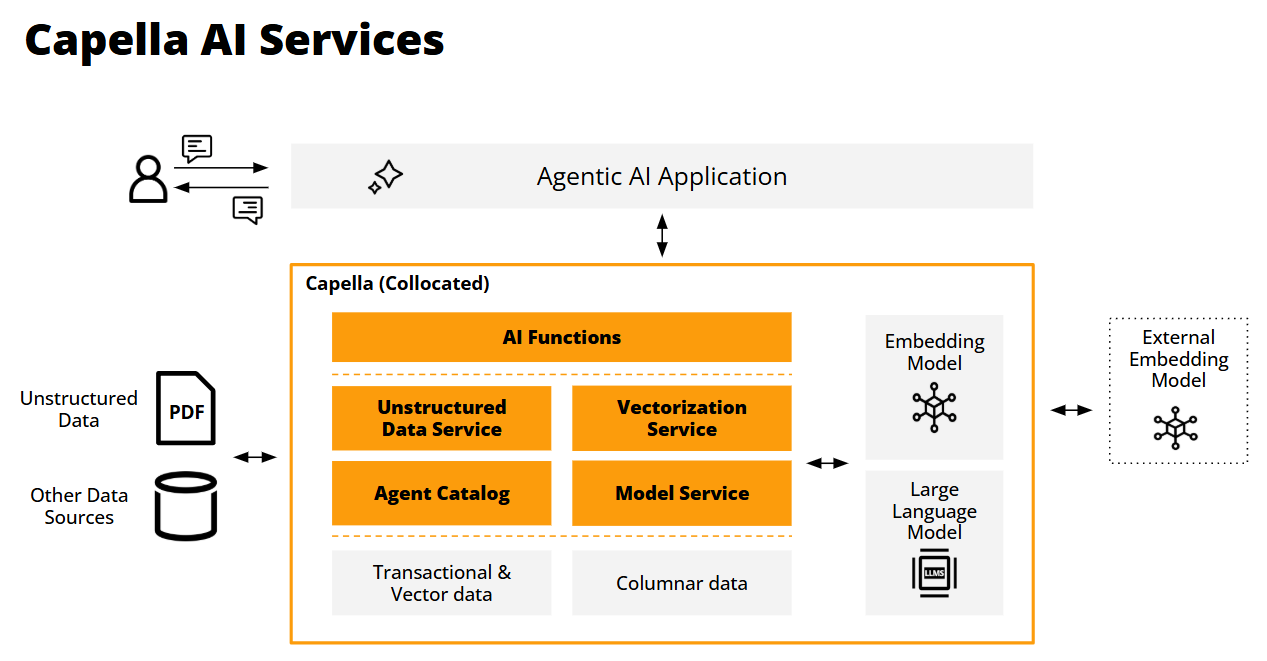
O Couchbase tem o prazer de anunciar uma série de novos serviços de IA que aprimorarão a Plataforma Capella para ajudar os desenvolvedores a criar e implantar Com tecnologia GenAI agentes e aplicativos autênticos. Os agentes são programas autônomos projetados para usar interações de linguagem natural para executar tarefas ou resolver problemas, tomando decisões com base em dados, trocas de conversas com grandes modelos de linguagem e contexto ambiental - tudo sem envolvimento humano.
Os agentes não apenas processarão entradas textuais, mas também incorporarão informações visuais e de áudio na execução de suas tarefas. Os serviços de IA da Capella ajudarão os desenvolvedores com muitas das etapas de processamento de dados necessárias ao usar técnicas de geração aumentada de recuperação (RAG) e aproveitarão as inúmeras ferramentas e estruturas do ecossistema RAG para interagir de forma eficaz com grandes modelos de linguagem. Além disso, esses serviços darão suporte a arquitetos e equipes de DevOps no gerenciamento da operação de agentes ao longo do tempo.
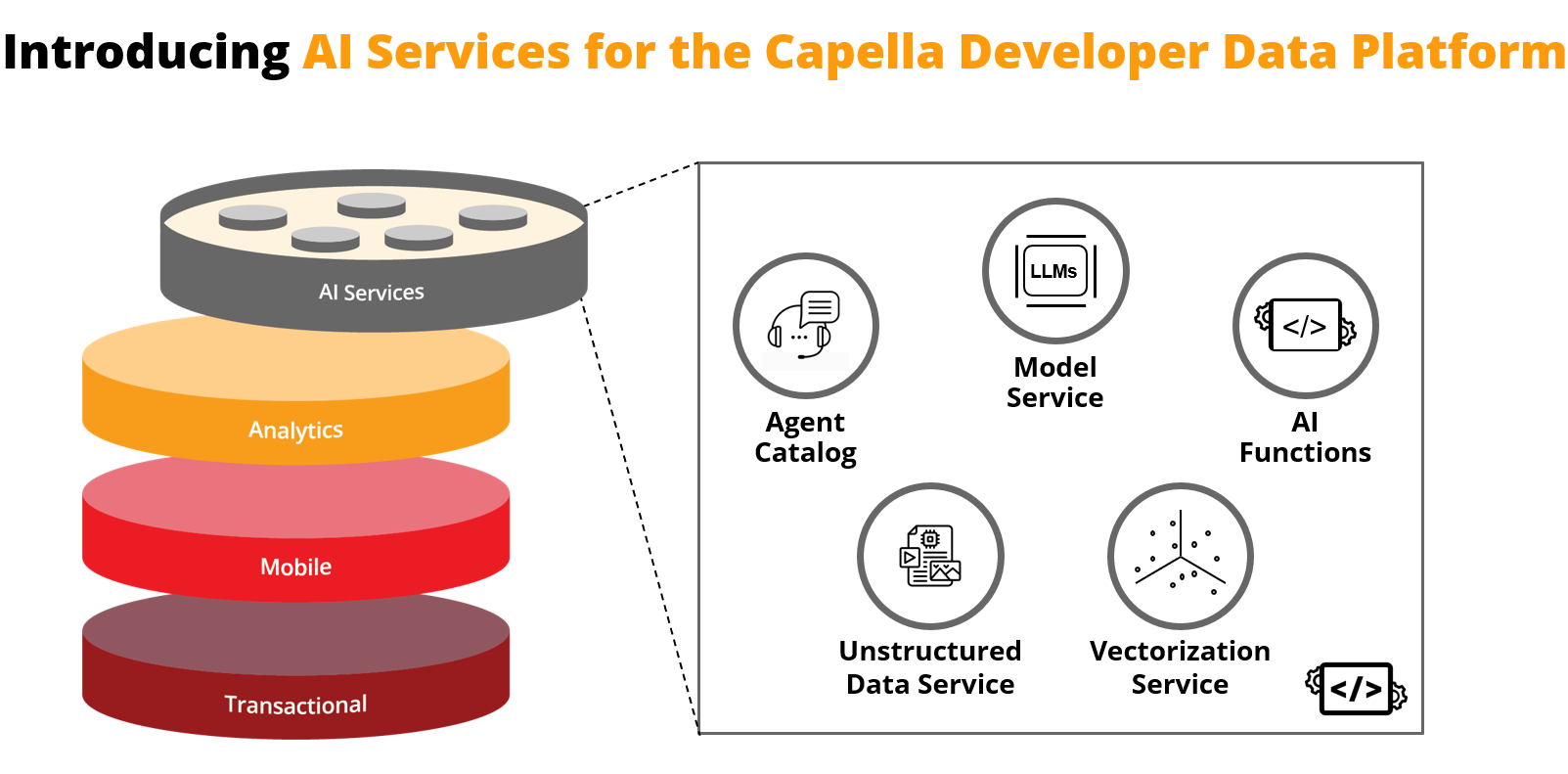
Novos serviços de IA da Capella
-
- Serviço de modelo: Hospedagem de modelos de linguagem externa, local e incorporada para minimizar as latências de processamento, aproximando os modelos dos dados e de seu consumo. Essa abordagem ajuda a lidar com os riscos de privacidade, consistência e compartilhamento de dados, garantindo que os dados nunca saiam da VPC do cliente. A Capella hospedará modelos do Mistral e do Llama3.
- Serviço de vetorização: Para criar, transmitir, armazenar e pesquisar embeddings de vetores para aprimorar a qualidade e a precisão das conversas e facilitar os contextos de interação contínua à medida que os LLMs evoluem e podem perder o contexto.
- Serviço de dados não estruturados: Transforma dados não estruturados, como documentos de texto, PDFs e tipos de mídia, como imagens e gravações, em "pedaços" de informações semânticas legíveis (por exemplo, frases e parágrafos) para gerar vetores utilizáveis. Essa etapa de pré-processamento amplia a variedade de casos de uso que os agentes podem suportar.
- Catálogo de agentes: Acelera o desenvolvimento de aplicativos agênticos com um repositório centralizado de ferramentas, metadados, prompts e informações de auditoria para gerenciar o fluxo, a rastreabilidade e a governança do LLM. Além disso, automatiza a descoberta de ferramentas de agente relevantes para responder às perguntas dos usuários e reforça as proteções para trocas consistentes de agentes ao longo do tempo.
- Funções de IA: Aumente a produtividade do desenvolvedor integrando a análise de dados orientada por IA diretamente nos fluxos de trabalho dos aplicativos usando a sintaxe familiar do SQL++. Isso acelera a produtividade do desenvolvedor, eliminando a necessidade de ferramentas externas, codificação personalizada e gerenciamento de modelos. As funções de IA do Capella incluem sumarização, classificação, análise de sentimentos e mascaramento de dados.
Por meio de sua plataforma unificada de dados para desenvolvedores, o Couchbase capacita os clientes a fornecer seus aplicativos mais importantes nesse novo cenário orientado por IA, oferecendo um suprimento de dados persistente e com estado para interações de IA, funcionalidade de aplicativo de agente e o desenvolvimento e a manutenção contínuos desses sistemas.
Por que precisamos de serviços de IA?
O desenvolvimento e a operação de aplicativos agênticos introduzirão muitos novos desafios centrados em dados. Esses desafios incluem:
Trabalhar com a GenAI muda fundamentalmente os fluxos de trabalho diários dos desenvolvedores
Enquanto o conceito de agentes O desenvolvimento de agentes requer novas técnicas além do RAG para garantir um comportamento confiável e fidedigno. Isso envolve manter um comportamento consistente em cada agente e em cada troca de LLM para invocações contínuas de agentes ao longo do tempo. Em vez de simplesmente projetar aplicativos alimentados por banco de dados, os desenvolvedores precisarão incorporar interações agênticas entre os bancos de dados e a funcionalidade do aplicativo. Nossos novos serviços de IA ajudarão os desenvolvedores a tirar proveito desses novos fluxos de trabalho e a se tornarem proficientes no uso de LLMs em seu desenvolvimento.
Todos devem aprender novas tecnologias e técnicas operacionais
A criação de funcionalidades baseadas em IA introduz novos fluxos de trabalho, integrações e processos de desenvolvimento no ciclo de vida atual de desenvolvimento de software. As interações de IA se tornarão programáticas, e novos tipos de dados, como vetores, serão gerados e consumidos durante essas trocas. Os novos serviços de IA introduzidos no Couchbase Capella ajudarão os desenvolvedores e arquitetos a lidar com esses novos processos, incluindo a automação de RAG (Retrieval Augmented Generation)A IA também inclui a construção de prompts, proteções para prompts e respostas, rastreamento de respostas, observabilidade do agente e validação da precisão do LLM. Os serviços de IA da Capella ajudarão o DevOps a garantir que os agentes estejam fazendo o que esperamos e não criando surpresas.
Interface de gerenciamento baseada na web do Capella AI Services
Oferta de dados proprietários para modelos privados
De acordo com nossas conversas com os clientes, a coisa mais assustadora sobre a GenAI é compartilhar dados que não deveriam ser compartilhados publicamente. Mas, em muitos casos, os dados proprietários da empresa são necessários para garantir que o conhecimento do LLM seja o mais preciso e contextual possível. Isso pode exigir o ensino do modelo com dados comerciais confidenciais e proprietários que não podem ser divulgados publicamente. Para atender a esse requisito, os LLMs devem ser privatizados ou hospedados de forma privada e não expostos ao público. Para atender a essa necessidade, a Capella hospedará modelos de idiomas de forma privada em nome dos clientes.
Conversas intensivas com LLMs
O Vector Search e os assistentes de chatbot são apenas os primeiros aplicativos da GenAI. Eles representam interações únicas com um modelo de linguagem. O que veremos em um futuro próximo é a evolução do RAG para englobar uma explosão de várias trocas com LLMs, semelhante a uma multidão de conversas de ida e volta. Também veremos agentes trabalhando em conjunto como um conjunto, conversando com vários modelos em várias conversas contínuas para concluir tarefas maiores e mais complexas. Quando aprendemos sobre o RAG pela primeira vez, ele foi apresentado como um fluxo de trabalho de caminho único com muitas etapas. Na realidade, os fluxos de trabalho dos agentes serão recursivos e muito mais complexos.
Redução da latência para melhorar a experiência do usuário
A latência é inimiga da IA. Ela é especialmente intolerável quando pessoas reais estão envolvidas. Como mencionamos anteriormente, esperamos reduzir a latência hospedando modelos juntamente com seu fornecimento de dados. Assim como a Netflix, acreditamos que o conteúdo deve ser processado perto de onde é consumido - nos dispositivos móveis dos usuários. Uma grande vantagem do Capella é que ele oferece um armazenamento de dados local, o Couchbase Lite, para processar trocas LLM diretamente nos dispositivos. Isso ajudará a manter os usuários satisfeitos, pois eles não terão que esperar exclusivamente pela resposta dos LLMs hospedados na nuvem.
Pré-processamento de dados não estruturados antes da vetorização
É essencial incorporar dados estruturados e não estruturados no processo de RAG. Dados não estruturados, como arquivos PDF, não estão imediatamente prontos para serem consumidos por um LLM. Esses dados devem ser analisados, divididos em partes lógicas e transformados em texto simples ou JSON antes de serem inseridos em um modelo de incorporação ou na base de conhecimento de um LLM. Isso geralmente é chamado de "pré-processamento e fragmentação" ou preparação de dados não estruturados para inclusão nos processos RAG de um agente. A Capella oferecerá um serviço de dados não estruturados para preparar objetos como PDFs para serem usados como fontes de incorporação de vetores e sua indexação. Durante esse processo, extraímos metadados importantes, dividimos e vetorizamos os dados com base em seu conteúdo semântico e geramos embeddings vetoriais de alta qualidade para insights de IA.

Fluxo de trabalho baseado na Web para gerenciar dados não estruturados por meio de serviços de IA
Vetorização: criação e transmissão de vetores em tempo real
Uma vez processados, esses dados não estruturados, além de dados operacionais e semiestruturados regulares, podem ser inseridos em um modelo de incorporação para criar índices de vetores (vetores) que servem como guias contextuais em um prompt para um LLM. O processo de criação de vetores como um serviço de fluxo contínuo permite a definição de contexto em tempo real e a criação de vetores à medida que o agente é executado. A quantidade de dimensões de vetores e de incorporação pode ser imensa, podendo chegar a bilhões. Esse volume representará desafios para as plataformas de dados existentes que não estão preparadas ou não foram projetadas para lidar com essa escala.
A especialização impulsionará a necessidade de muitos modelos e muitos agentes
Os desenvolvedores precisarão rastrear os programas que interagem com os modelos de IA, pois os modelos evoluirão com o tempo. Para manter seu conhecimento atualizado, os modelos de linguagem precisarão se tornar menores para que possam reduzir seus ciclos de aprendizado. À medida que os modelos se especializam, eles também se tornarão mais focados em tópicos ou contextos específicos, como um modelo que prevê padrões climáticos, avalia resultados de exames médicos ou entende leis específicas da física. Da mesma forma, os agentes também se tornarão especializados em sua funcionalidade. Isso criará a necessidade de um índice de catálogo que mantenha diferentes agentes e suas interações com modelos especializados.
Manutenção de um contexto persistente ao longo do tempo
Os agentes de longa duração precisarão de persistência de dados para garantir que os resultados ou saídas do agente permaneçam consistentes e conforme o esperado ao longo do tempo. Isso é um desafio porque os modelos de linguagem grandes não mantêm o contexto de uma conversa para outra. Eles precisam ser informados novamente sobre seu contexto de sessão para sessão, o que exige que as conversas sejam preservadas.
O conhecimento do LLM muda com o tempo, e os agentes precisam de barreiras de proteção
O que complica ainda mais o problema da preservação de dados é o fato de que o conhecimento em um LLM é dinâmico e crescente, o que significa que o modelo pode não fornecer a mesma resposta a um prompt de um momento para o outro. Portanto, os desenvolvedores devem incorporar rotinas de verificação de confiabilidade para verificar os resultados esperados e a consistência das trocas de LLM ao longo do tempo. Isso significa que a conversa de LLM de ontem deve ser preservada e mantida para que possa ser usada como dados de validação para a interação de LLM de hoje. Isso significa que as interações do agente com os LLMs - juntamente com suas entradas, saídas de resposta e metadados contextuais - devem ser preservadas para cada conversão para uma validação de precisão adicional. Isso gerará uma grande quantidade de dados que precisam ser armazenados em um Banco de dados pronto para IA, como o Couchbase.
A criação de um agente envolve a seleção de um LLM para raciocínio e chamada de função, o gerenciamento de ferramentas e dados, a manutenção de prompts, a otimização com cache e a iteração para obter qualidade. O Catálogo do Couchbase Agent integra-se perfeitamente à Capella Developer Platform para simplificar esse processo, reduzindo a carga cognitiva dos desenvolvedores. Nosso catálogo de vários agentes ajuda os desenvolvedores a gerenciar ferramentas, conjuntos de dados, modelos, verdade básica e avisos entre agentes. Ele oferece suporte à seleção de ferramentas semânticas para consultas, fornece ferramentas pré-construídas e oferece a melhor infraestrutura de serviço de modelos da categoria para hospedar LLMs. Os recursos adicionais incluem aplicação de guardrail, detecção de alucinação, auditoria de linhagem de consulta, previsão e integração do RAG-as-a-Service (RAGaaS) para avaliação da qualidade do agente.
Minimização dos custos das conversas do LLM
As conversas com LLMs serão caras e lentas. Os agentes participarão de inúmeras conversas com os LLMs, o que torna isso um desafio significativo. É por isso que cada CSP está entusiasmado com os modelos que eles suportam (Bedrock/Claude, Gemini, ChatGPT) como futuros geradores de receita. Com o desempenho do agente, os milissegundos custam dinheiro. O Couchbase aproveitará várias vantagens de desempenho já incorporadas ao Capella para tornar as interações com o LLM mais rápidas e econômicas. Isso inclui a capacidade de armazenar em cache consultas comuns para prompts, minimizando acessos redundantes a um LLM e oferecendo armazenamento em cache semântico e de conversação dos resultados do LLM para respostas comuns. O Capella também oferece recursos de ajuste de desempenho, como dimensionamento multidimensional e replicação entre centros de dados. Esperamos que o Capella ofereça uma vantagem atraente de preço/desempenho aos clientes.
Analisando mais a fundo os desafios e as oportunidades, Stephen O'Grady, analista principal da RedMonk, disse: "À medida que a IA continua a transformar a empresa, ela está apresentando novos desafios significativos para a infraestrutura. Para aplicar a IA em seus negócios existentes, as empresas precisam integrar fontes de dados grandes e díspares e uma série de modelos de IA em rápida evolução usando fluxos de trabalho complicados. Isso criou a demanda por uma plataforma de dados alternativa e multimodal com acesso não apenas aos dados de treinamento necessários, mas também aos modelos a serem aplicados a eles. Essa é a oportunidade para a qual os novos Capella AI Services da Couchbase foram criados."
Conclusão: Bem-vindo ao nosso mundo de IA!
A Couchbase está expandindo sua plataforma de dados de desenvolvedor para incluir uma série de serviços de IA para dar suporte à criação e à operação de aplicativos autênticos. Esses serviços atendem a várias necessidades urgentes de persistência e organização de dados quando os agentes estão em execução e simplificam muitas das dores de cabeça que os desenvolvedores enfrentam no estágio inicial ao criá-los. Esses serviços serão oferecidos a clientes e clientes em potencial qualificados como uma prévia privada. Estamos extremamente empolgados com o que estamos apresentando para oferecer suporte a aplicativos essenciais neste novo mundo de IA. Venha participar desse passeio!
Para obter mais informações
-
- Leia o comunicado à imprensa
- Confira Serviços de IA da Capella ou Inscreva-se no Prévia privada
- Blog: O que é RAG?
- Blog: O que é um agente de IA?
- Registre-se para o webcast: Um roteiro para a nova era dos agentes de IA - desafios e oportunidades
